Overview#
The conversation around AI in manufacturing tends to gravitate toward the cloud: large models, large datasets, large infrastructure.
That narrative makes sense for strategic use cases: predictive maintenance trained on years of historian data, quality inspection powered by computer vision pipelines, demand forecasting fed by ERP exports. Those workloads belong in the cloud.
In fact, we had the chance to showcase exactly that:
But there is a quieter, more immediate opportunity sitting right at the edge, inside the middleware layer that connects machines and third-party interfaces to the MES.
It is where OPC-UA tags become structured events, where protocol translations happen, where business rules fire in low-code tasks. The data is already there. The question is whether we can make it more accessible.
This post explores how Small Language Models (SLMs) can be embedded directly into Connect IoT to unlock natural language interaction with the edge runtime: without a cloud dependency, without a GPU, and without leaving the shopfloor network.
The goal is not to show a definitive approach, but to showcase a building block that can be used to create powerful agentic workflows.
Large Models vs Small Models#
To understand why SLMs are interesting at the edge, it helps to first understand what differentiates them from their larger counterparts.
Large Language Models (LLMs) — GPT-Models, Claude, Gemini — are general-purpose models trained on vast datasets covering virtually every domain of human knowledge. They are remarkably capable and can reason across complex, multi-step problems. They also require significant compute: tens to hundreds of gigabytes of memory, often a GPU, and for hosted versions, a reliable internet connection. Running them locally on edge hardware is currently impractical in most industrial environments.
Small Language Models (SLMs) are a different trade-off. Models like Llama 3.2 3B, Phi-4 Mini, Gemma 3 4B, or Qwen2.5 3B fit comfortably in 2–4 GB of RAM, run acceptably fast on a standard CPU, and can be quantized to run efficiently on modest hardware. They sacrifice some general reasoning capability, but for a focused, well-scoped task they can perform remarkably well.
The key insight for manufacturing is that we do not need a model that can write poetry or explain philosophy. We need a model that can understand a question about what is currently happening on a machine, look at the available data, and give a useful answer. That is a narrower problem and SLMs are well-suited for it.
The pace of innovation in large language models has been remarkable.
Yet as frontier models grow more capable, a parallel trend is emerging: the rise of optimized, smaller models.
These models sacrifice breadth and raw power for efficiency, and that trade-off is often exactly what a real-world problem demands.
A useful way to think about model selection is through the lens of problem scope.
At one extreme, narrow and well-defined problems are best served by classical mathematical algorithms, such as linear regression or decision trees, where the solution space is predictable and mappable. As problems grow more complex, with higher dimensionality and harder-to-formalize relationships, tailored machine learning models become the right tool. Move further still into problems that are semantic, contextual, or linguistic in nature, and language models enter the picture.
Within that last category, scope still matters. A model that needs to reason across domains as wide as gardening and astrophysics requires a large language model, trained on vast and diverse content. But a model operating within a specific domain, say, legal document review or industrial maintenance, can be a small, fine-tuned language model that is faster, cheaper, and often more accurate within its lane.
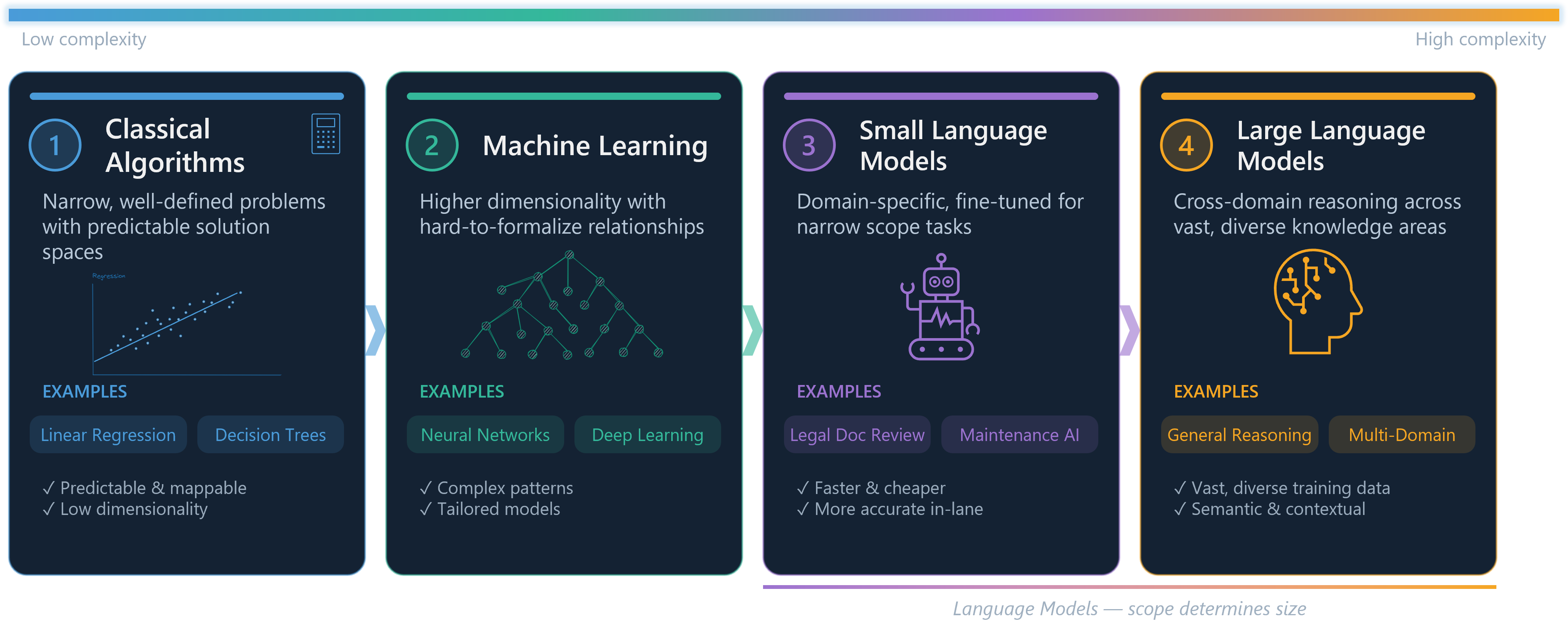
The key insight is that bigger is not always better. Matching model capability to problem scope is not a compromise, it is good engineering.
The LLMs are the Mainframe and the SLMs are the PCs.
Why the Edge Is the Right Place#
CM MES Connect IoT typically, runs as part of the edge infrastructure. In many deployments the Automation Manager runs on a server on the shopfloor network, close to the machines it integrates. Even in cases where the MES is deployed in the cloud. It has direct access to driver state, controller variables, event history, and everything flowing through its low-code tasks.
We had the opportunity to show case this scenario where we had the AutomationManager deployed in a on edge microshift cluster and the CM MES on cloud openshift cluster:
Keeping inference at the edge brings several concrete advantages:
Latency. A question about what a machine is currently doing deserves an answer in milliseconds, not in the round-trip time to a cloud endpoint. On a busy shopfloor network with intermittent connectivity, cloud inference is simply unreliable for operational queries.
Data sovereignty. Shopfloor data is often sensitive — process parameters, cycle times, quality results, equipment identifiers. Many customers operate under strict policies about what can leave the plant network. A locally running model never transmits that data anywhere.
Offline resilience. Machines do not stop running because the internet is down. An edge-deployed SLM is available whenever the Automation Manager is running, regardless of external connectivity.
Cost. Cloud LLM APIs are priced per token. For a conversational interface that operators might query dozens of times a shift across multiple lines, those costs accumulate quickly. Local inference has no marginal cost per query.
Connect IoT as the Context Provider#
The value of an SLM at the edge is entirely dependent on the quality of context it receives. A language model does not magically know what is happening on your shopfloor, it reasons over whatever information you provide in its prompt.
Connect IoT is already the system that aggregates that information. The Automation Manager holds in memory the current state of every variable defined across its controllers and drivers. Every tag read from OPC-UA, every message received over MQTT, every value written by a low-code task — all of it is accessible through the internal memory of the running manager.
With this as context:
A natural language query like “What is the spindle doing and should I be concerned?” becomes a reasonable, answerable question.
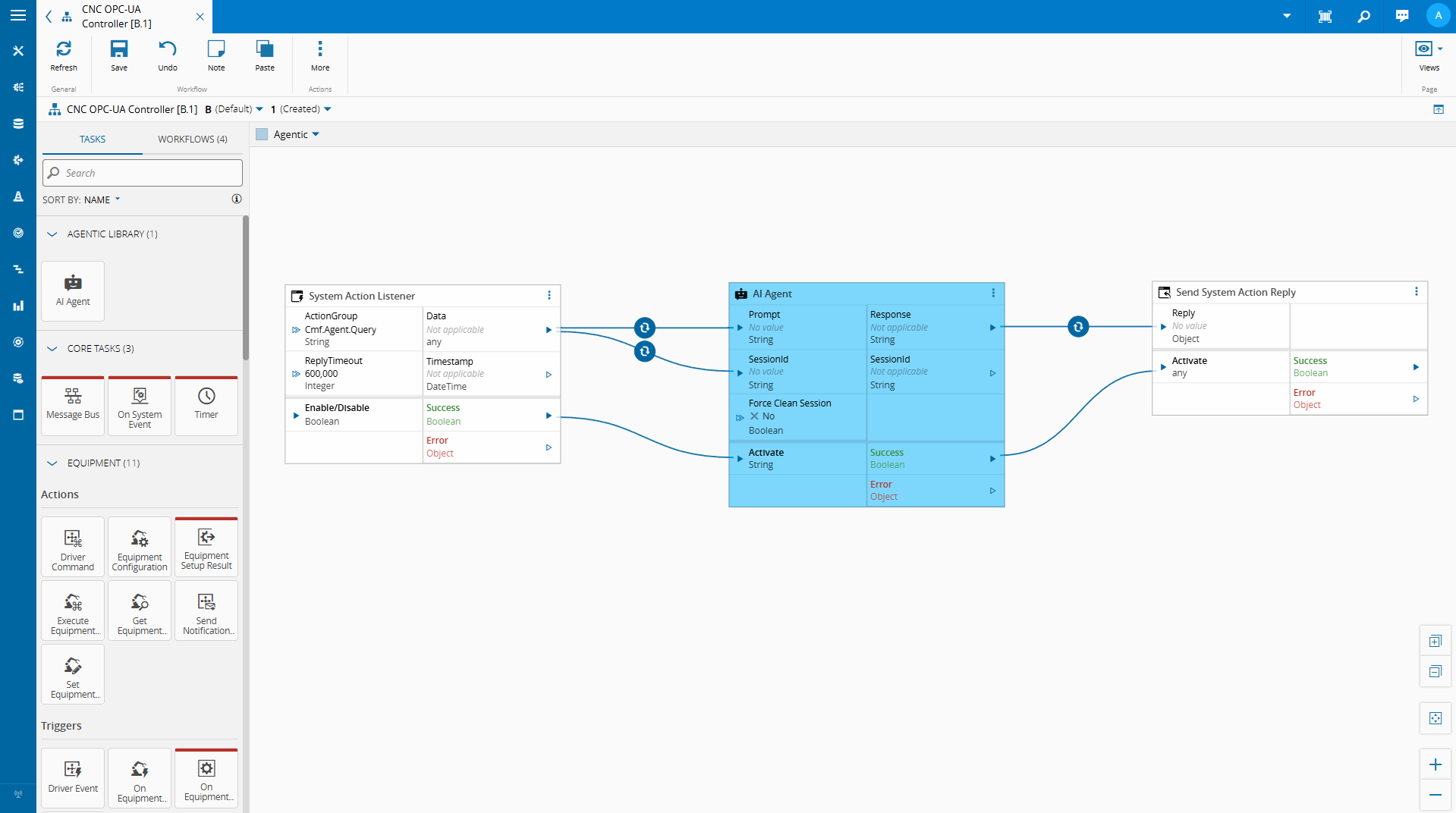
Low-Code Tasks as the Integration Point#
One of the strengths of Connect IoT’s low-code model is its extensibility. Automation Controllers are composed of tasks, discrete units of logic that read variables, make decisions, call external services, and write outputs back into the controller state.
This extensibility is what makes SLM integration natural. We can implement a custom task that:
- Reads variables from the controller’s current state
- Serializes that state into a structured context payload
- Passes a user query and that context to a locally running SLM
- Returns the model’s response as a task output or controller variable
From the low-code editor’s perspective, this is just another task with an input and an output. The complexity of local model inference is encapsulated behind a clean API.
The model is not replacing the low-code logic — it is augmenting the operator’s ability to interact with it.
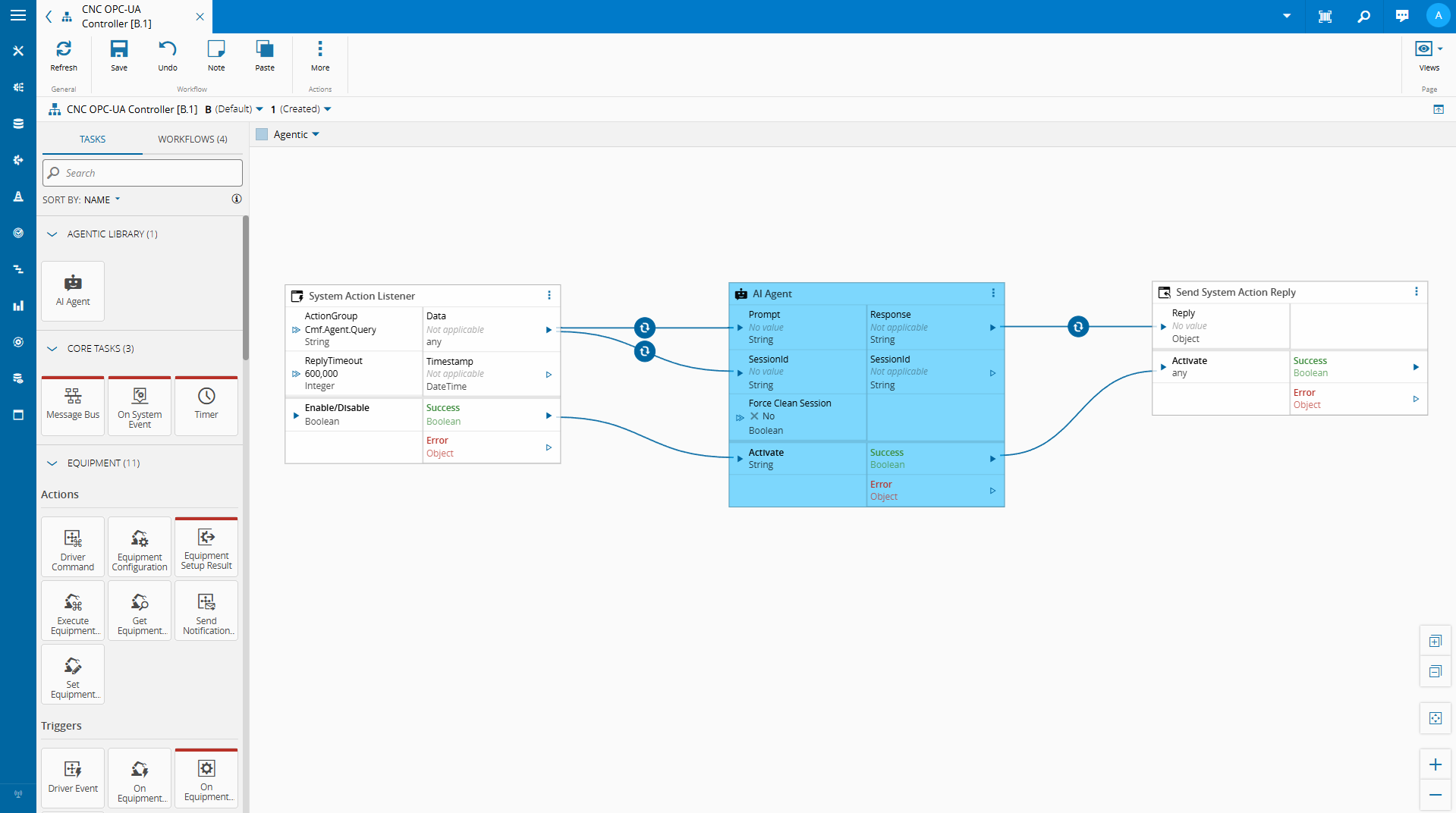
We are able with the low code integration and some metadata, to leverage what the MES provides out of the box to create a quick implementation where we can chat with our on edge integration.
Looking Ahead#
In this example we were able to leverage the CM MES low code platforms to quickly create an implementation of edge AI that provides value.
Edge AI does not have to mean complex infrastructure. Sometimes it means a small model, a structured prompt, and the right integration point.