Overview#
The proliferation of Unified Namespace (UNS) architectures in manufacturing has solved fundamental challenges in real-time data distribution.
However, the transition from raw telemetry to actionable intelligence remains problematic. We will take a look at a case study of ProveItBeverage to try to illustrate it. ProveItBeverage is a multi-site beverage manufacturer.
We aim to demonstrate how schema-full ingestion into a Canonical Data Model (CDM) enables the transformation of stateless event streams into contextual information suitable for AI-driven knowledge extraction. We examine the theoretical foundations of this transformation through the lens of the DIKW hierarchy and present an architectural framework that bridges operational technology with analytical intelligence.
 |
|---|
| DIKW Pyramid — Image source: https://www.jeffwinterinsights.com/insights/dikw-pyramid |
Introduction#
The Fourth Industrial Revolution and the diminishing costs of sensors and micro-controllers in the last decades, has brought unprecedented connectivity to manufacturing environments. Sensors, programmable logic controllers, and edge devices now generate continuous streams of operational data. The Unified Namespace paradigm, built upon publish-subscribe messaging protocols such as MQTT, has emerged as the dominant architectural pattern for distributing this data across enterprise systems.
Yet connectivity alone does not yield intelligence.
Manufacturing organizations increasingly report a paradox: more data has not produced proportionally better decisions. Production managers possess access to real-time dashboards yet struggle to answer fundamental questions about operational performance. The barrier is not access but comprehension — raw data lacks the semantic structure necessary for meaningful analysis.
The missing element is schema-driven contextualization.
Through examination of a demo production implementation at ProveItBeverage, we demonstrate how ingesting UNS events into a Canonical Data Model creates the informational foundation upon which artificial intelligence can perform genuine knowledge extraction.
Fundamental Concepts#
DIKW Hierarchy#
The Data-Information-Knowledge-Wisdom (DIKW) hierarchy, provides a useful framework for understanding the transformation of raw observations into actionable understanding. In manufacturing contexts, this hierarchy manifests as follows:
┌───────────────────────────────────────────────────────────────────┐
│ WISDOM │
│ Strategic decisions informed by accumulated insight │
├───────────────────────────────────────────────────────────────────┤
│ KNOWLEDGE │
│ Patterns, correlations, and causal relationships │
│ discovered through analytical reasoning │
├───────────────────────────────────────────────────────────────────┤
│ INFORMATION │
│ Contextualized events with temporal, spatial, │
│ and relational attributes │
├───────────────────────────────────────────────────────────────────┤
│ DATA │
│ Raw sensor values, timestamps, discrete measurements │
└───────────────────────────────────────────────────────────────────┘
Figure 1. The DIKW hierarchy applied to manufacturing intelligence
The critical observation is that transitions between levels require transformation, not merely accumulation. Data becomes information through contextualization. Information becomes knowledge through pattern recognition and inference. Each transition requires different computational and architectural capabilities.
The Semantic Gap in UNS Architectures#
Unified Namespace architectures excel at the distribution of data but are intentionally agnostic regarding semantic structure. A topic hierarchy such as enterprise/site/area/resource/metric provides locational context but does not embed:
- Temporal state: Previous values and duration of current condition
- Operational context: Active production orders, shift boundaries, maintenance windows
- Causal relationships: Events that precipitated the current observation
- Comparative baselines: Historical norms against which to evaluate current performance
This semantic gap represents the primary barrier to AI-driven analytics. Machine learning models and large language models require structured, contextual data to perform meaningful inference. Without such structure, these systems are limited to surface-level retrieval rather than genuine knowledge extraction.
ISA-95 as Semantic Foundation#
The ISA-95 standard (IEC 62264) provides an internationally recognized framework for manufacturing system integration. Its hierarchical model — Enterprise, Site, Area, Work Center, Work Unit — offers a semantic vocabulary that both humans and machines can interpret consistently.
By anchoring data models in ISA-95 semantics, manufacturing organizations establish a shared ontology that enables:
- Cross-system interoperability without custom mapping
- Human-comprehensible data organization
- Machine-readable hierarchical relationships
- Vendor-agnostic data exchange
ProveItBeverage#
Organizational Context#
ProveItBeverage is a beverage manufacturing enterprise operating three production facilities. The organization sought to implement an analytics platform capable of answering operational questions through natural language interaction — a capability requiring sophisticated data infrastructure.
| Facility | Production Areas | Resources | Daily Event Volume |
|---|---|---|---|
| Plant1 | 5 | 22 | ~1.7M events |
| Plant2 | 5 | 17 | ~1.0M events |
| Plant3 | 5 | 11 | ~0.6M events |
Table 1. ProveItBeverage facility characteristics
Each facility follows an identical four-stage production flow: Liquid Processing, Filler Production, Packaging, and Palletizing. This standardization enabled cross-plant performance comparison — a key analytical requirement.
Initial State: Raw UNS Implementation#
ProveItBeverage’s initial implementation utilized MQTT-based UNS for real-time data distribution. Equipment across all facilities published metrics to a centralized broker using a standardized topic hierarchy:
proveitbeverage/{site}/{area}/{resource}/metrics/{metric_type}
This architecture successfully addressed real-time visibility requirements. Operators could observe current equipment states through dashboard applications subscribing to relevant topics.
However, analytical queries proved problematic. When production managers asked questions such as “What caused the performance drop on Pallet01 yesterday afternoon?”, the system could not respond. The UNS contained only point-in-time values; reconstructing the narrative of events required manual correlation across thousands of discrete messages.
The Transformation Challenge#
The fundamental challenge was transforming stateless message streams into stateful event narratives. Consider the following UNS message:
{
"topic": "proveitbeverage/Plant1/Palletizing/Pallet01/metrics/oee",
"payload": { "value": 0.64, "timestamp": "2026-02-12T14:30:00Z" }
}
This message communicates a fact but not a story. To understand its significance, an analyst must determine:
- What was the previous OEE value?
- How long has performance been at this level?
- Is this within normal operational variance?
- What other events correlate temporally?
- Which production order and product were active?
Answering these questions from raw UNS data requires reconstructing state from message history, a computationally expensive operation that becomes intractable at scale.
Architectural Solution#
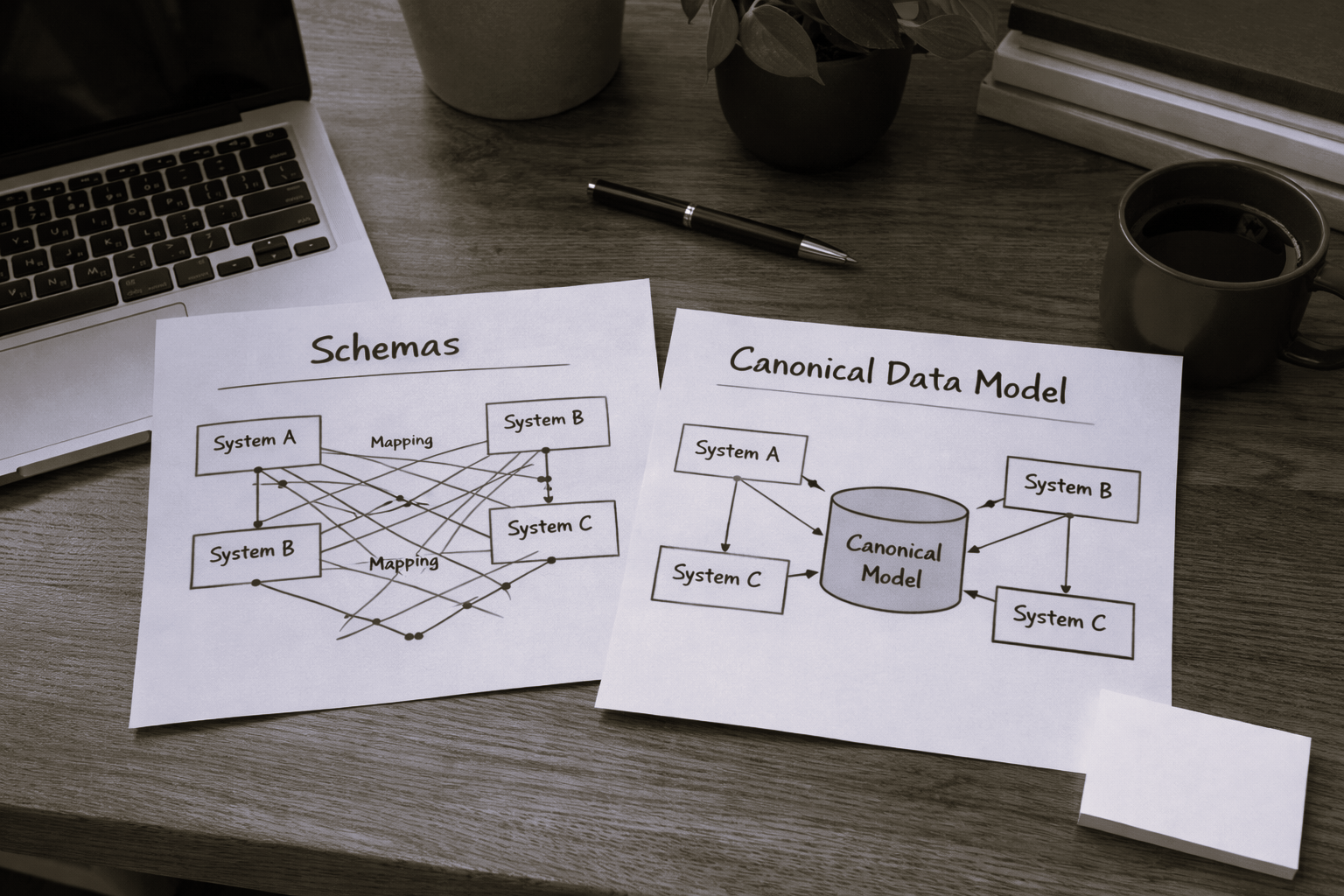
The Canonical Data Model#
ProveItBeverage implemented a Canonical Data Model (CDM) as an intermediary layer between UNS ingestion and analytical systems. The CDM restructures manufacturing data around self-describing events rather than point-in-time measurements.
┌─────────────────────────────────────────────────────────────────────────┐
│ CDM EVENT STRUCTURE │
├─────────────────────────────────────────────────────────────────────────┤
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ ┌─────────────┐ │
│ │ Event │ │ Hierarchy │ │ Metrics │ │ Previous │ │
│ │ Metadata │ │ Context │ │ Payload │ │ State │ │
│ ├─────────────┤ ├─────────────┤ ├─────────────┤ ├─────────────┤ │
│ │ eventType │ │ enterprise │ │ oee │ │ priorOee │ │
│ │ eventTime │ │ site │ │ availability│ │ priorTime │ │
│ │ eventId │ │ area │ │ performance │ │ duration │ │
│ │ source │ │ resource │ │ quality │ │ │ │
│ └─────────────┘ └─────────────┘ └─────────────┘ └─────────────┘ │
│ │
│ ┌─────────────────────────────────────────────────────────────────┐ │
│ │ Operational Context │ │
│ ├─────────────────────────────────────────────────────────────────┤ │
│ │ shift: "Afternoon" | workOrderId: "WO-2026-0847" | product: ... │ │
│ └─────────────────────────────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────────────┘
Figure 2. Canonical Data Model event structure
Each CDM event encapsulates:
- Explicit hierarchy conforming to ISA-95 semantics
- Embedded previous state eliminating downstream state reconstruction
- Operational context linking measurements to business entities
- Self-describing metadata enabling schema-aware processing
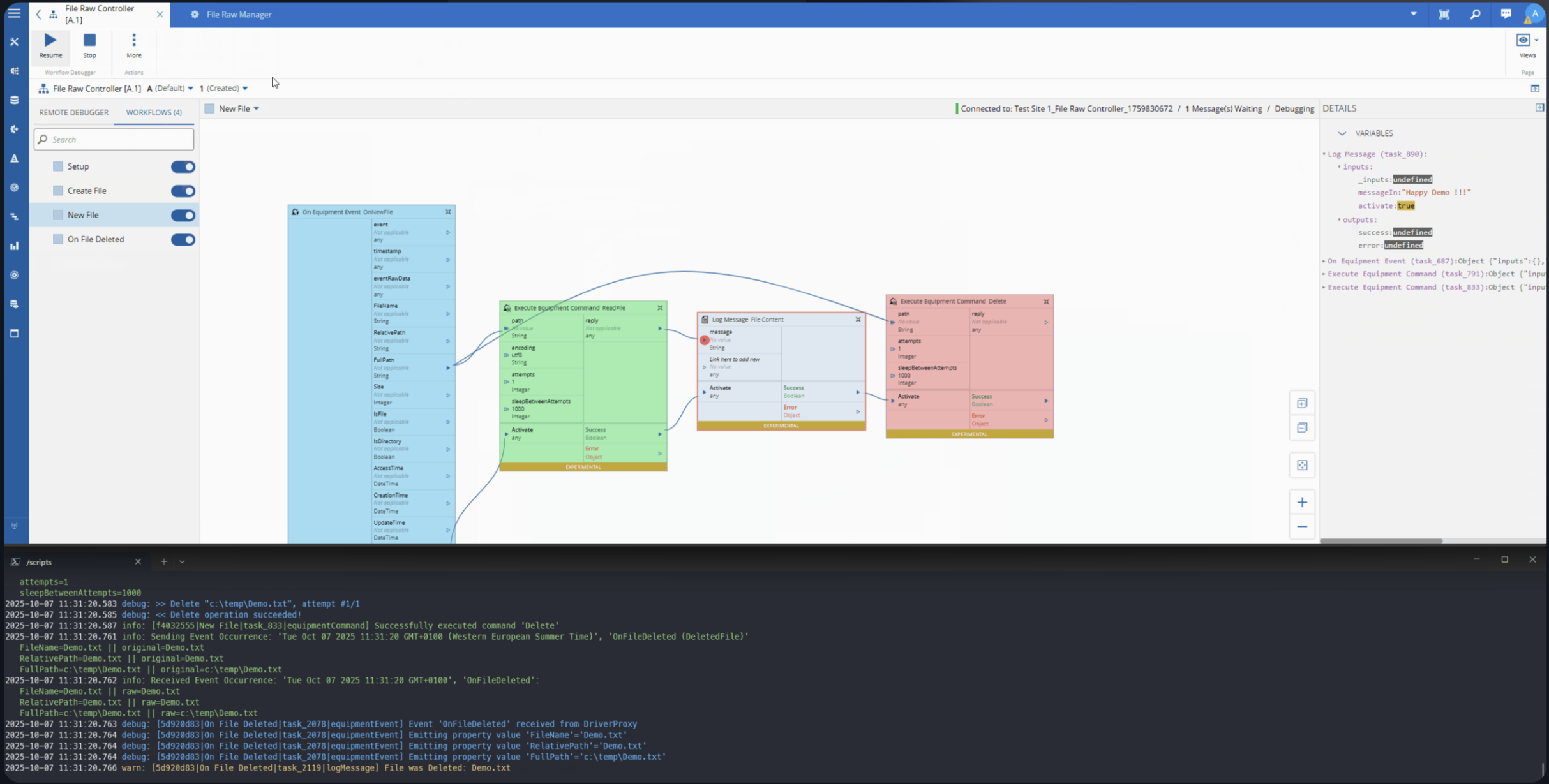
Ingestion Architecture#
The transformation from UNS messages to CDM events occurs through a low-code automation workflow deployed as a containerized service. The architecture maintains clear separation between data distribution (UNS), transformation (automation layer), and storage (Enterprise Data Platform).
┌──────────────┐ ┌──────────────────────────────┐ ┌──────────────┐
│ │ │ AUTOMATION LAYER │ │ │
│ UNS/MQTT │ │ ┌────────────────────────┐ │ │ ENTERPRISE │
│ BROKER │───> │ │ 1. Topic Subscription │ │────> │ DATA │
│ │ │ │ 2. Hierarchy Parsing │ │ │ PLATFORM │
│ Stateless │ │ │ 3. MES Context Query │ │ │ │
│ Messages │ │ │ 4. State Enrichment │ │ │ CDM Event │
│ │ │ │ 5. Schema Validation │ │ │ Store │
│ │ │ │ 6. CDM Transformation │ │ │ │
│ │ │ └────────────────────────┘ │ │ │
└──────────────┘ └──────────────────────────────┘ └──────────────┘
│
▼
┌──────────────────────────────┐
│ OBSERVABILITY LAYER │
│ Ingestion metrics, latency, │
│ error rates, throughput │
└──────────────────────────────┘
Figure 3. UNS-to-CDM ingestion architecture
The automation workflow anf MES performs the following transformations:
- Topic Parsing: Extracts ISA-95 hierarchy from MQTT topic structure
- Context Enrichment: Queries MES for active shift, work order, and resource state
- State Embedding: Retrieves previous metric values and calculates state duration
- Schema Validation: Ensures conformance to CDM event specifications
- Publication: Transmits validated events to the Enterprise Data Platform
This transformation executes within milliseconds, preserving the real-time characteristics of the source data while adding the semantic richness required for analytics.
The Enterprise Data Platform#
CDM events flow into an Enterprise Data Platform (EDP) designed for both operational querying and analytical aggregation. The platform maintains:
- Event Store: Immutable log of all CDM events, indexed by hierarchy and time
- Aggregation Layer: Pre-computed KPIs (OEE, availability, performance, quality) at configurable time granularities
- Query Interface: SQL and GraphQL endpoints for programmatic access
This dual-layer architecture supports both real-time operational queries (“What is the current state of Pallet01?”) and historical analytical queries (“What was the average OEE trend over the past week?”).
AI-Driven Knowledge Extraction#
The Analytics Copilot#
With CDM events providing structured, contextual information, ProveItBeverage implemented CM MES and its EDP with Analytics Copilot, a natural language interface powered by large language models. The system utilizes Model Context Protocol (MCP) servers to provide the LLM with, safe and guarded, query access to both real-time events and aggregated metrics.
┌─────────────────────────────────────────────────────────────────────────┐
│ ANALYTICS COPILOT ARCHITECTURE │
├─────────────────────────────────────────────────────────────────────────┤
│ │
│ ┌───────────────┐ ┌───────────────┐ ┌─────────────┐ │
│ │ USER │ │ LARGE │ │ MCP │ │
│ │ QUERY │────────>│ LANGUAGE │────────> │ SERVERS │ │
│ │ │ │ MODEL │ │ │ │
│ │ "What caused │ │ │ │ ┌─────────┐ │ │
│ │ the drop in │<────────│ Reasoning & │<──────── │ │SQL MCP │ │ │
│ │ performance?"│ │ Synthesis │ │ │(Events) │ │ │
│ └───────────────┘ └───────────────┘ │ ├─────────┤ │ │
│ │ │GraphQL │ │ │
│ │ │MCP(KPIs)│ │ │
│ │ └─────────┘ │ │
│ └─────────────┘ │
└─────────────────────────────────────────────────────────────────────────┘
Figure 4. Analytics Copilot query architecture
From Information to Knowledge#
The transition from information retrieval to knowledge extraction is observable in the system’s response characteristics.
Consider the following query:
“Create a report for Site Plant1 Area Palletizing Resource Pallet01 of the last two days.”
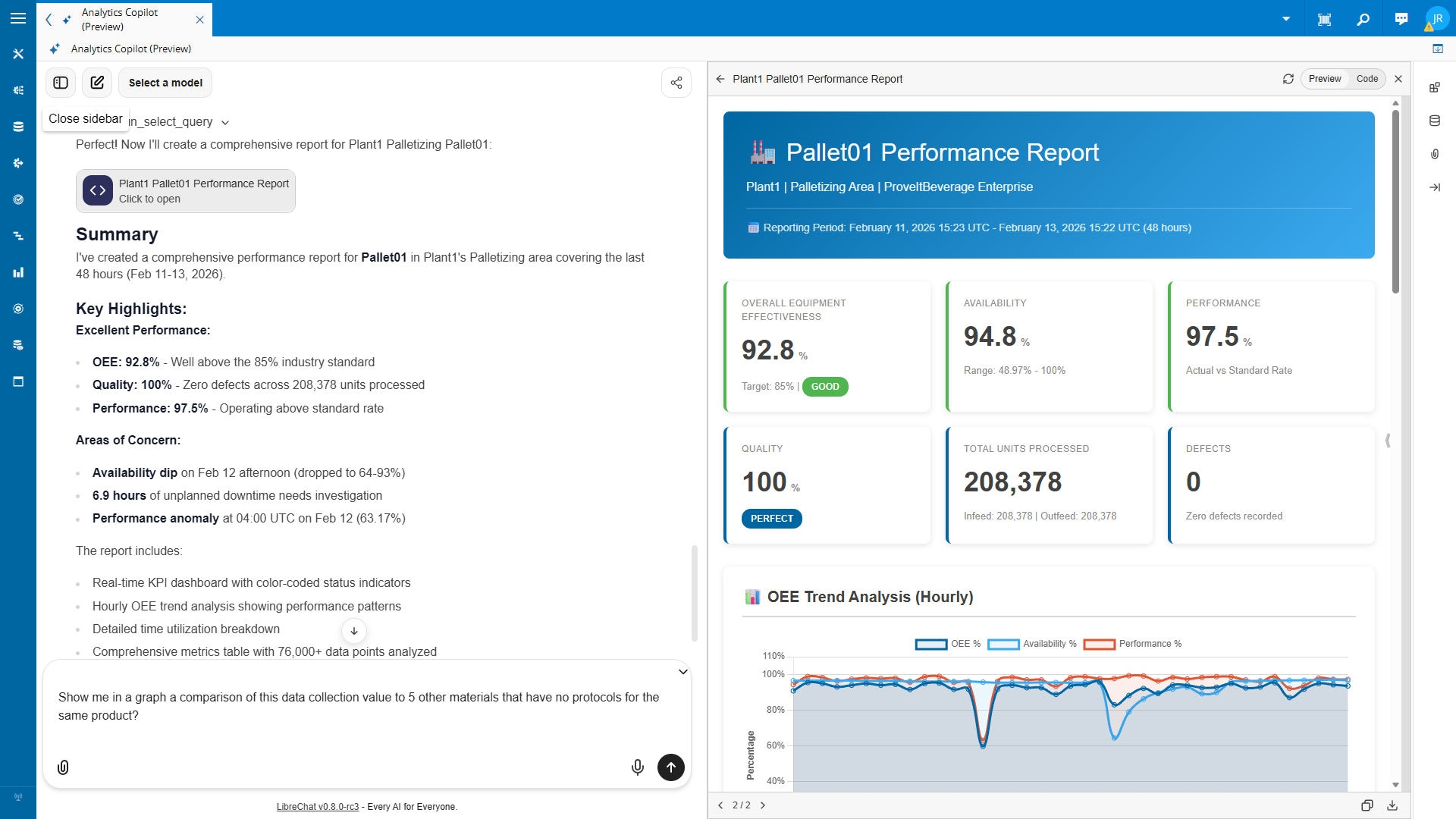
Generated by AI:
A traditional BI system would return tabular data or pre-configured visualizations. The Analytics Copilot, operating on CDM-structured data, produces analytical synthesis:
Performance Summary (Feb 11-13, 2026)
- Overall Equipment Effectiveness: 92.8% (exceeds 85% benchmark)
- Quality Rate: 100% across 208,378 units processed
- Performance Efficiency: 97.5% relative to standard rate
Anomaly Detection
- Availability degradation identified: Feb 12, 14:00-18:00 UTC
- Performance anomaly: 63.17% at 04:00 UTC on Feb 12
- Cumulative unplanned downtime: 6.9 hours
Causal Hypothesis
- Availability drops correlate temporally with shift transitions
- Pattern consistent across multiple observation periods
Recommendations
- Investigate shift handoff procedures
- Schedule preventive maintenance inspection
- Implement automated anomaly alerting
Generated by AI:
This response demonstrates knowledge-level output: the system has identified patterns, formulated hypotheses about causation, and generated actionable recommendations. Such synthesis is only possible because the underlying data carries sufficient context for the model to reason about manufacturing reality.
Comparative Analysis#
The Copilot’s capacity for cross-resource analysis further illustrates the value of schema-driven ingestion. When queried about Palletizing area performance, the system produced comparative insights:
| Resource | OEE | Assessment |
|---|---|---|
| Wrapper (Plant1, Plant2) | 100% | Optimal performance |
| Pallet01 | 93.79% | Above benchmark |
| Pallet02 | 94.20% | Above benchmark |
| Robot (Plant1) | 17.82% | Significant underperformance |
| Robot (Plant2) | 11.83% | Critical issue |
| Workstation (Plant1) | 0.82% | Near non-operational |
Table 2. Palletizing resource comparative analysis
The system independently identified that workstation resources across all plants exhibit critically low OEE, suggesting either systematic data collection issues or fundamental operational problems requiring investigation. This insight emerged from pattern recognition across the CDM event corpus, a capability impossible with unstructured UNS data.
Discussion#
Schema as Enablement#
The ProveItBeverage implementation challenges a common misconception: that schema enforcement represents bureaucratic overhead. In practice, the CDM schema functions as an enablement layer — constraints that guarantee downstream systems can reason about data without defensive programming or complex validation logic.
Every CDM event is guaranteed to contain its hierarchical context, its previous state, and its operational associations. This guarantee eliminates an entire class of analytical failures stemming from missing or inconsistent data.
Architectural Implications#
The success of this implementation suggests several architectural principles for manufacturing intelligence systems:
- Separation of distribution and semantics: UNS should remain semantically lightweight; contextualization occurs at ingestion boundaries
- State embedding over state reconstruction: Downstream systems should not bear responsibility for maintaining state machines
- Schema conformance as contract: The CDM schema represents a contract between data producers and analytical consumers
- ISA-95 as lingua franca: Industry-standard hierarchies reduce integration complexity and enable cross-system reasoning
Limitations and Future Work#
This case study examined a relatively homogeneous manufacturing environment with standardized processes across facilities. In a more heterogeneous environments with diverse equipment types and non-standard processes, the impact would be even bigger.
Conclusion#
The journey from raw manufacturing data to AI-driven knowledge extraction is not a matter of algorithmic sophistication alone. It requires disciplined attention to data architecture — specifically, the transformation of stateless event streams into contextual, self-describing information structures.
The ProveItBeverage case demonstrates that schema-full ingestion into a Canonical Data Model provides the semantic foundation upon which artificial intelligence can perform genuine analytical reasoning. Without such structure, AI systems are limited to retrieval; with it, they can identify patterns, formulate hypotheses, and generate actionable recommendations.
As manufacturing organizations invest in AI capabilities, they would be well served to examine their data foundations with equal rigor. The sophistication of the analytical layer is ultimately bounded by the quality of information it receives. Intelligence, in this sense, is not a feature to be added but an emergent property of well-architected systems.
Related Resources: