This blog post will be a very high level and utilitarian overview of machine learning and its application in the shopfloor.
Overview#
It’s important to understand what is happening when we are making predictions and why is machine learning different from other approaches.
The first step when trying to make accurate predictions about reality is to trim down and narrow our scope of prediction. We break down the phenomenon into a set of inputs that are the context and set of outputs which are the result or outcome of our prediction.
Let’s imagine a simple example of just that. We want to predict housing prices.
Using a statistical approach, we can postulate that housing prices have something to do with the size of the house.
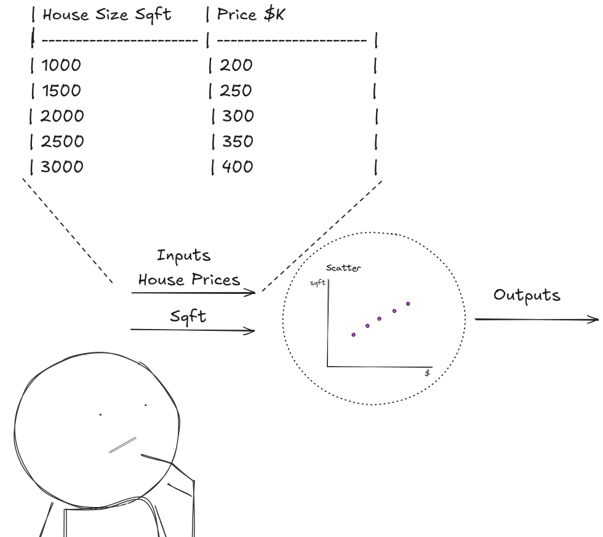
We can say that as inputs we will have house size and house prices. We look at the data and formulate a hypothesis (in this case a linear regression) and say “Each additional 500 sqft increases price by about $50,000”. Therefore, we can say that being Y, the price of a house and X the size of a house, the price of a house can be calculated with Y=100+0.1X.
Now we can predict a house price, just by knowing its size, for example if I have a house of 2200 sqft: Y=100+0.1(2200)=320.
This example is very simple and rudimentary. Nevertheless, it already constructs an important way of thinking. We understand intuitively that we have inputs, and that our goal is to create a model of reality, that given those inputs is able to give us accurate predictions.
The problem we face in our day-to-day is that reality even for narrow problems is very complex. By complex we mean that it’s multi-variate in nature.
In our simple case we depend just of size, but anyone that has ever looked at buying a house knows that actually a house depends on many more factors. Using traditional deterministic or semi-deterministic models, we would try to collect as much relevant and meaningful inputs and create an explanation in the form of an equation that modelled reality.
If size is more important than, a pool, then size would be weighted more heavily. This method can become very complex and requires a deep knowledge of the object of study and how all factors interact with each other in order to construct a model.
As problems become more complex and dynamic other approaches surfaced. This is where machine learning comes from, an attempt to have an evolving probabilistic answer.
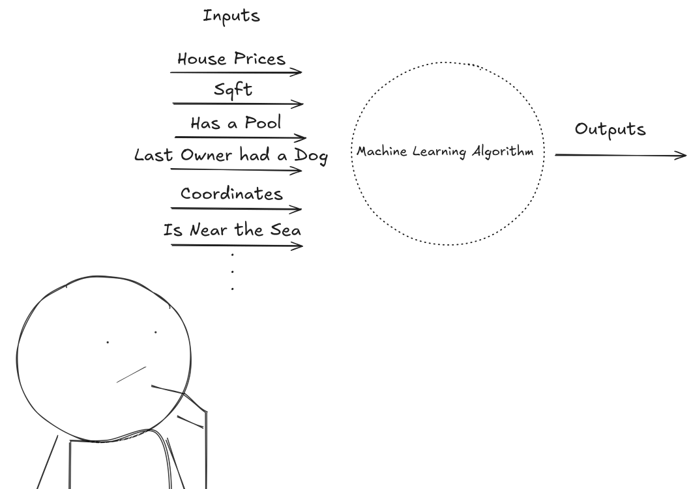
Now we gather all relevant datapoints, but instead of knowing the model and applying a formulaic approach, we will create a feedback mechanism to teach our model to fit to what the right answer is.
Machine Learning is an exploratory method, focused on describing reality, not on explaining reality. It is based on feedback mechanisms for auto correction in search of the model that best answers our queries. It has the ability to make predictions and to surface hidden relations or patterns.
Machine Learning#
Let’s try and understand what is machine learning, how it’s used and what are the goals and the methods.
Supervised Learning#
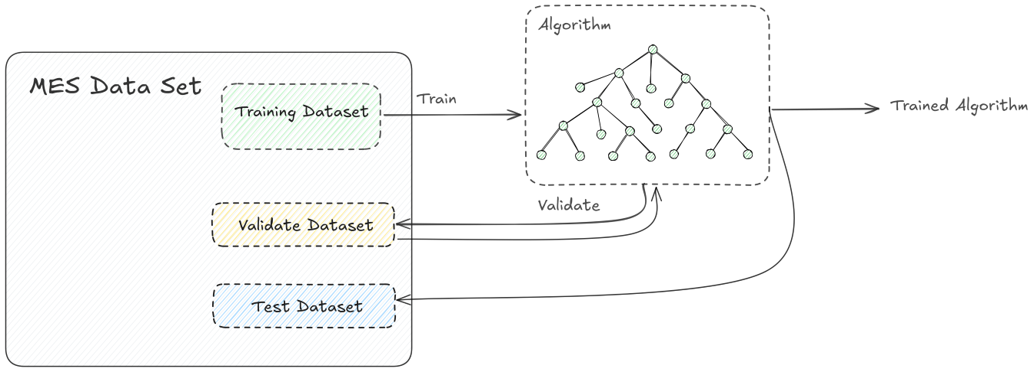
Is a type of machine learning that trains algorithms on labeled (every input has a matching output) data. The model is provided with a labeled dataset.
The algorithm will split the data into a percentage, to train, validate and test. The model will then try and make predictions and compare itself with the validation dataset, as the models receives the feedback of how accurate he is, he will readjust its internal weights to maximize his accuracy.
Let’s see a simple example of this. We have a dataset of fruit images and their matching names. The model will train and validate itself, after that when provided with an image of a fruit, in this case a strawberry he will be able to predict its name.

The interesting element here is that our image does not need to be one exactly like the one provided in the original dataset, but one close enough, that the model is able to understand it’s a strawberry. The model is not making deterministic claims he is making a weighted decision to provide the answer with the highest probability of being correct.

We can start seeing the value of machine learning. We departed from an original dataset and are now able to make predictions about items that are even outside our original dataset.
We use this in our day to day, google photos uses our photos as a dataset and when we catalog it with names to the faces, he is able to catalog and correctly identify our pictures.
In supervised learning, generically there are two different goals, let’s see what they are.
Classification#
Classification is when the model is optimized to try and sort elements into different categories. The simplest classification is binary, yes or no, true or false.
The model after training and validation will be able to predict, if for a given set of inputs, the output is either true or false.
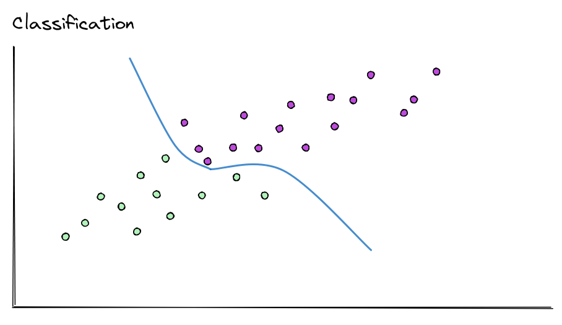
Here, our model can answer the question:
- Is this image a strawberry? It would then predict if it’s yes or no.
Another type is multiclass classification, here the elements are sorted into more than two categories. Here we would have several categories of fruits, and it would sort the strawberry in the correct category.
Regression#
Regression, the goal is to be able to predict a continuous numerical outcomes (like price, temperature, or sales) by finding the mathematical relationship between input features (independent variables) and the target (dependent variable) in historical data, essentially fitting the best line or curve to the data to make future predictions.
We’ve already seen this. In our housing example we were doing a linear regression, in order to predict housing prices.
In a regression the model is able to fit an algorithm into the best approach, in order to be able to predict the values of the output. It is possible that the model discovers that the best fit is some kind of linear regression, as the complexity increases the fitted curve can become more complex as well as it tries to fit in N dimensional fields.
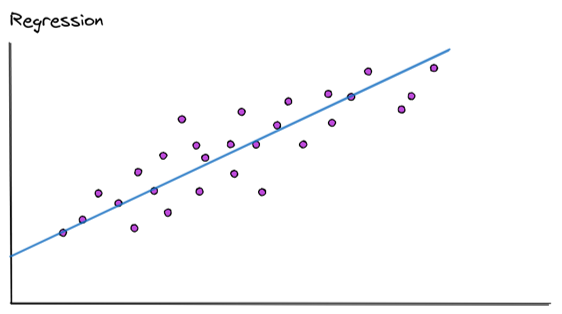
Our model, now is not answering things like if an image is or not a strawberry, but as we saw before trying to discover numerical values. Like house prices, temperatures, number of defects, etc.
Unsupervised Learning#
As we saw before, supervised learning is predicated on having a labeled (every input has a matching output) dataset that we use to train our model and then perform predictions. In unsupervised learning, our data is unlabeled. The goal here is to find patterns and relationships between the data.
If we have a dataset of unsorted data, with animal pictures, the goal of our model is to be able to create groups or clusters of animals.
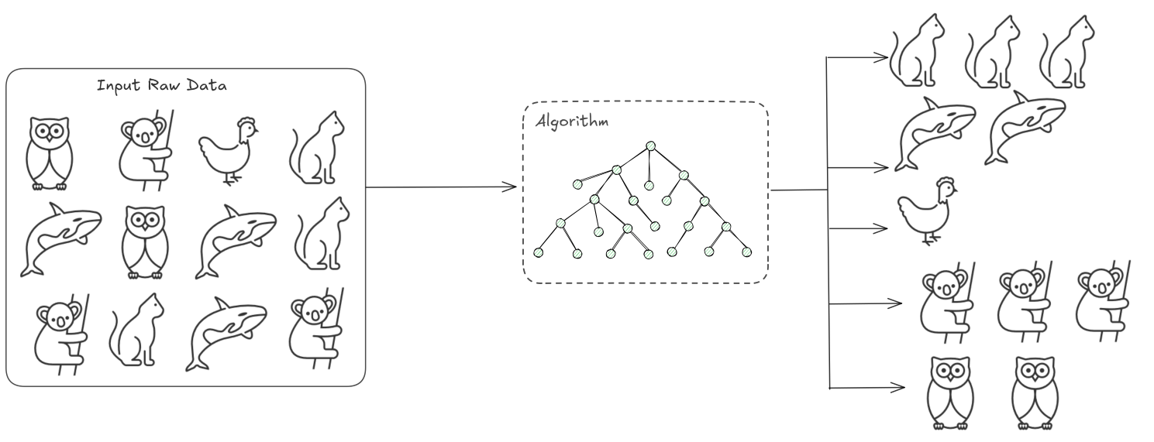
These models are very helpful. As we saw, they are used for:
Clustering: grouping unlabeled data; identify patterns and relationships.Association Rule Learning: understanding rules between relationships (i.e. customer that buys milk, also buys cereals).Dimensionality Reduction: reduce the number of features without losing information.
Machine Learning in the Shopfloor#
We saw the examples and types of algorithms in machine learning, but what do they have to do with reality of the shopfloor?
In manufacturing, data prediction has to be exploratory, not just purely deterministic and has to adapt to an ever changing reality. That is why machine learning shines in the shopfloor. It does not aim to perfectly determine why something happens and all the confounding factors, instead it focuses on describing reality well enough to make useful predictions.
A helpful way to frame it is:
- Statistics looks at data to validate hypotheses
- Machine learning looks at data to recognize patterns
Both are valuable, but machine learning aligns better with the variability, noise, and constant change of real production environments. Imperfect predictions, if early and actionable, are often far more valuable than perfect explanations that come too late.
Let’s get back to our types and see how they fit in the shopfloor reality.
Supervised Learning: Learning From Past Outcomes#
Supervised learning works with labeled data — data where the outcome is known.
On the shopfloor, this is extremely common.
We have several examples of classification in every shop-floor:
Pass / FailOK / Defective- Machine
Running / Stopped
We even have examples of multiclass classification:
- Material has Defect
A / B / C - Die has Quality
1 / 2 / 3
Regressions are also very common:
Yield valueProduction RateTemperature level
Typical goals:
- Classification: predict a category
Will this material fail inspection? - Regression: predict a continuous value
What will the final yield be?
Unsupervised Learning: Finding Patterns You Didn’t Define#
Unsupervised learning uses unlabeled data. No predefined answers — just observations.
This is useful when:
- You don’t yet know what “bad” looks like
- You want to understand variability
- You want to detect abnormal behavior early
Typical goals include:
- Clustering similar production runs or machine behaviors
- Pattern discovery across parameters
- Dimensionality reduction to identify what really matters
For engineers, unsupervised learning is often the first step to insight — helping define what should later become a supervised use case.
Data Quality: Where Most Machine Learnings Projects Go To Die#
The most common misconception about machine learning is that the hard part is choosing the algorithm.
In reality, the hardest part is data quality.
Machine learning requires:
Structured dataClear timestampsConsistent unitsContext(material, machine, process, operator)Minimal noise
This is exactly where an MES makes the difference.
An MES already:
- Enforces structure through process models
- Tracks genealogy end-to-end
- Normalizes events via canonical data models
- Eliminates ambiguity by design
Instead of cleaning spreadsheets or reconciling multiple sources, engineers get ML-ready data as a byproduct of execution.
Why Machine Learning Belongs Inside the MES#
An MES is uniquely positioned for machine learning because it sits at the intersection of:
- Data
- Process
- Action
MES:
- Controls the shopfloor
- Ingests equipment, material, and quality data
- Provides structured datasets
- Executes workflows in real time
MES Data Ingestion and Canonical Events#
In Critical Manufacturing MES, shopfloor data is ingested through canonical IoT event definitions.
This means:
- Equipment data
- Material movements
- Telemetry
- Defects
All follow a consistent structure.
As data flows in:
- Events are normalized and standard
- Context is added automatically
- Data is stored in a unified model
- Datasets are generated and reused
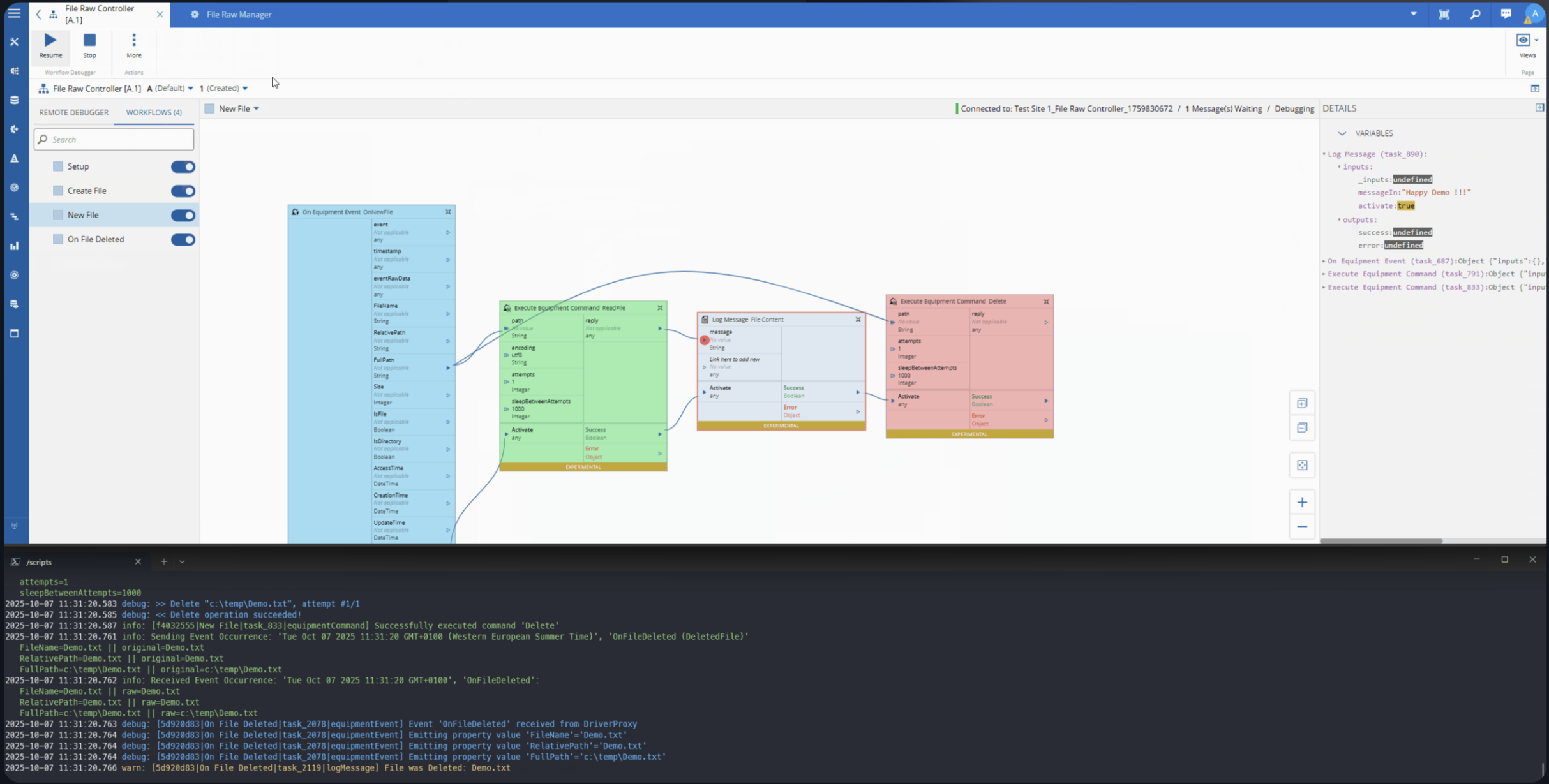
We can see how a simple change of Resource State generates a CDM event with all the contextual information.
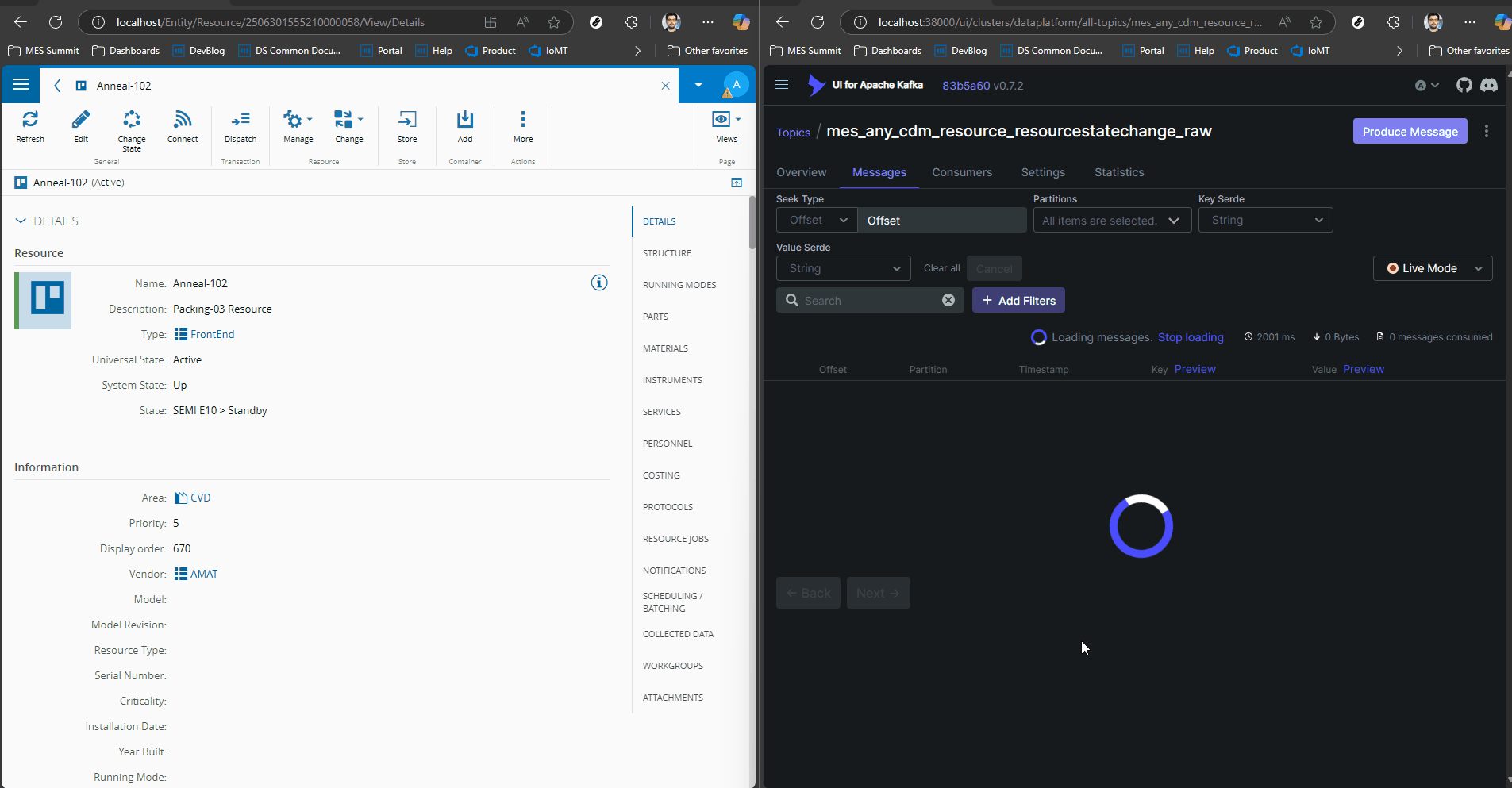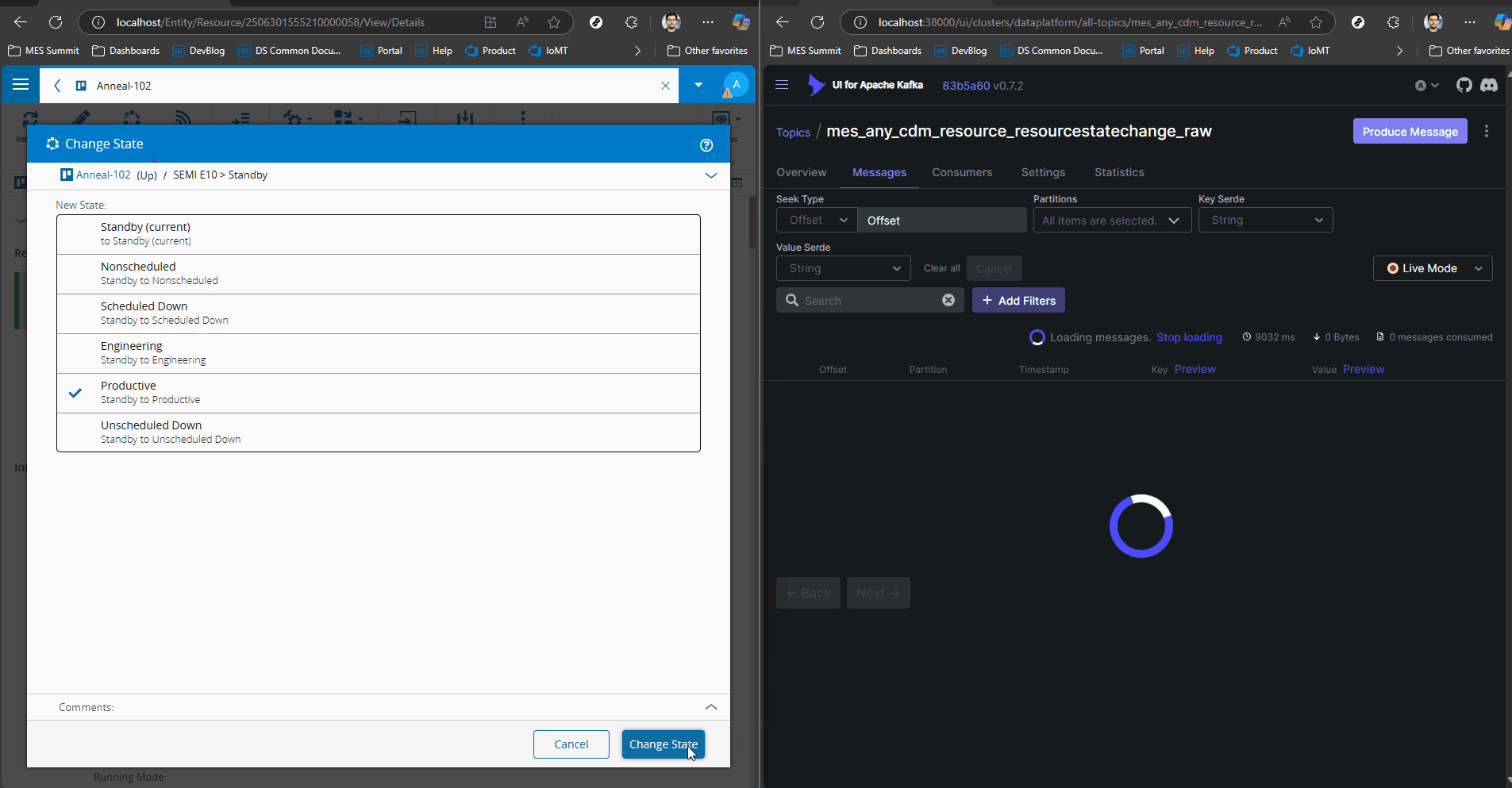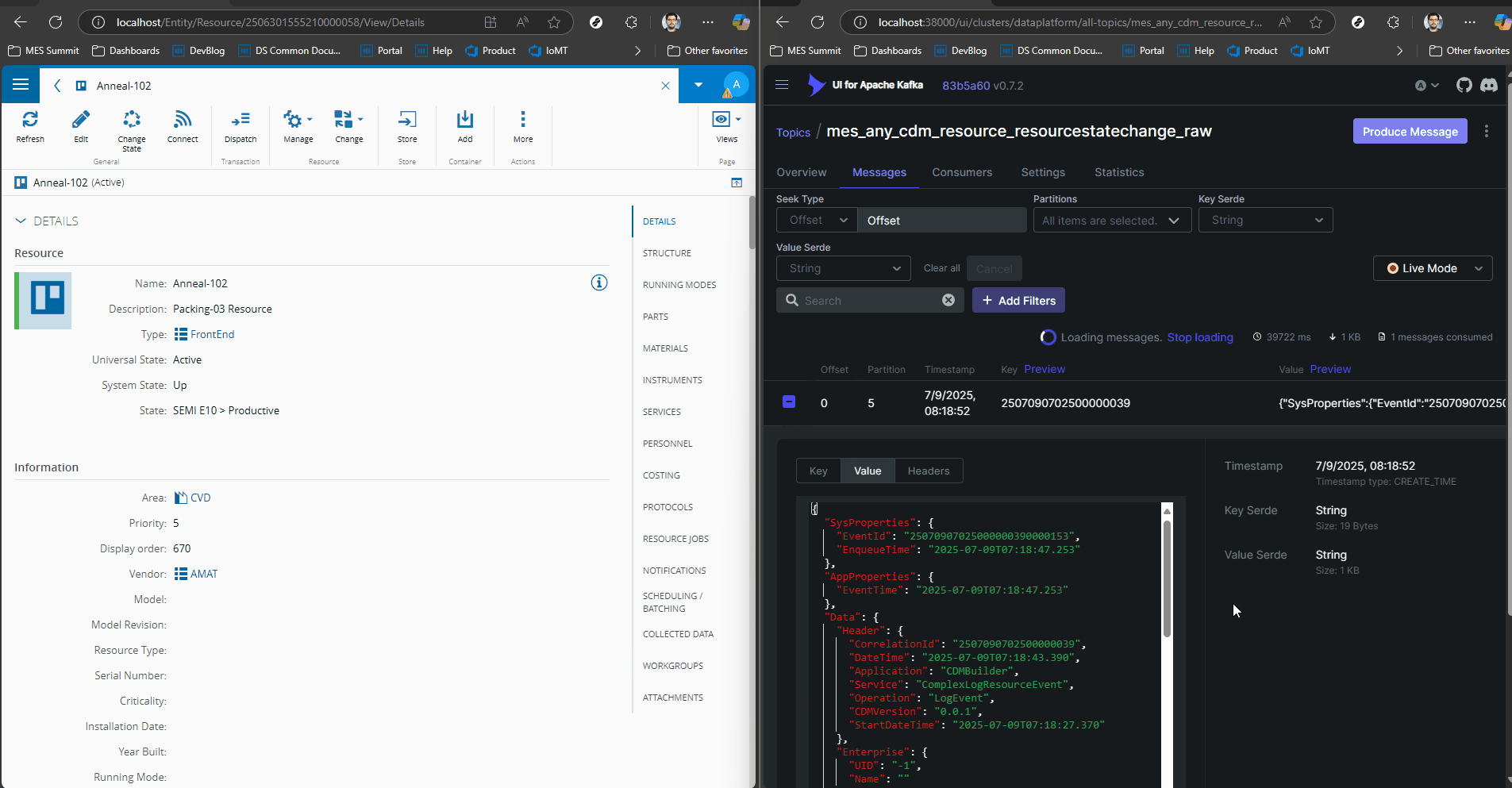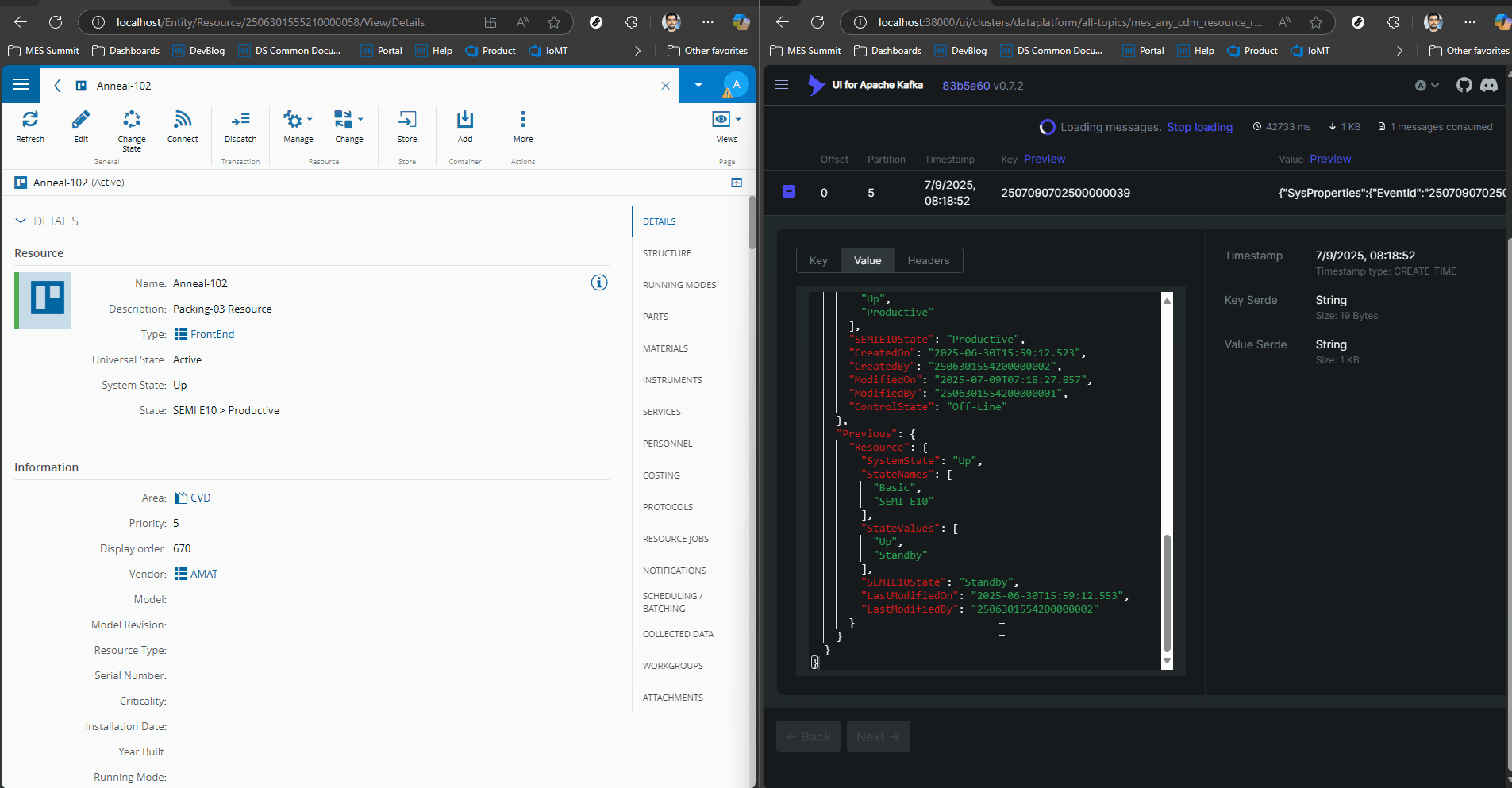
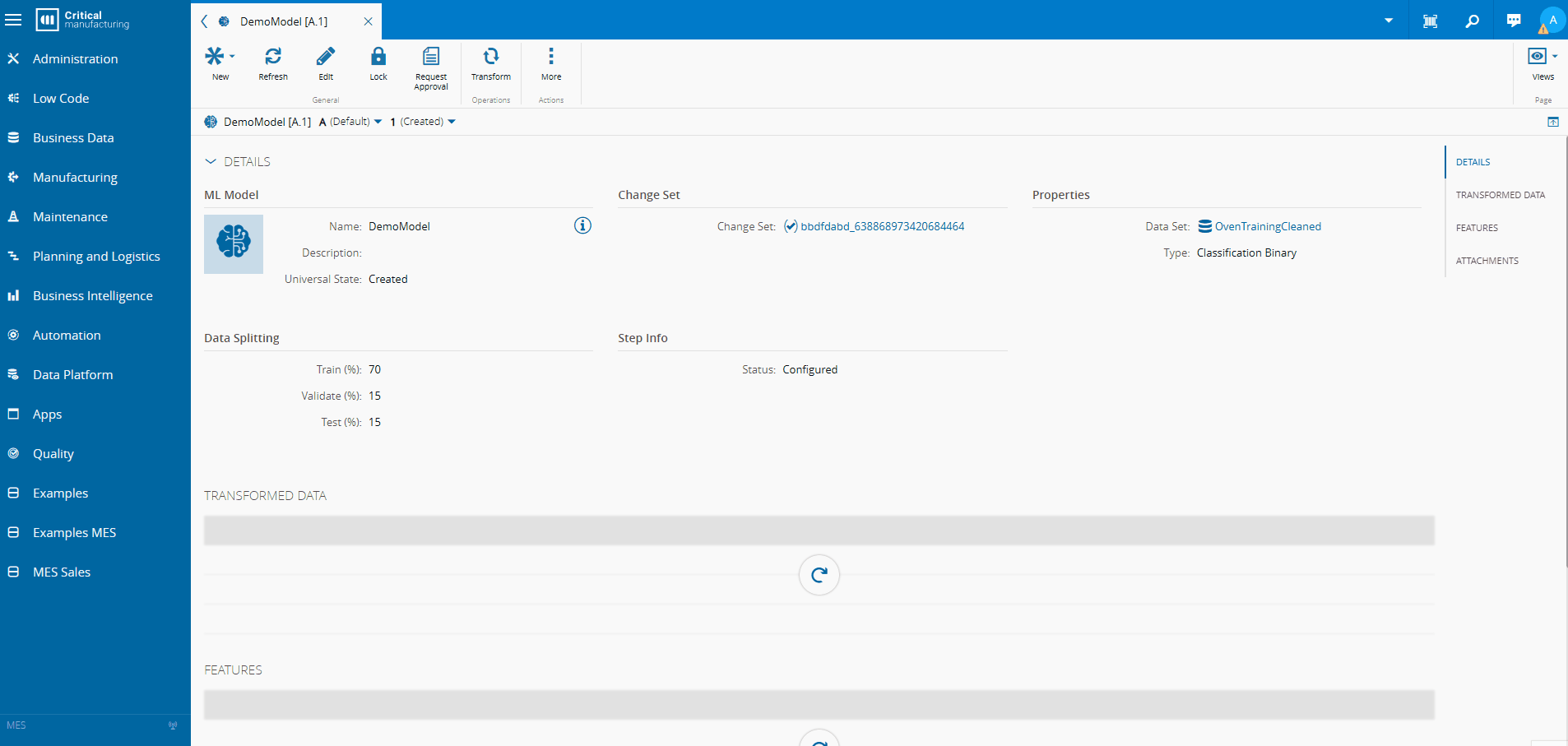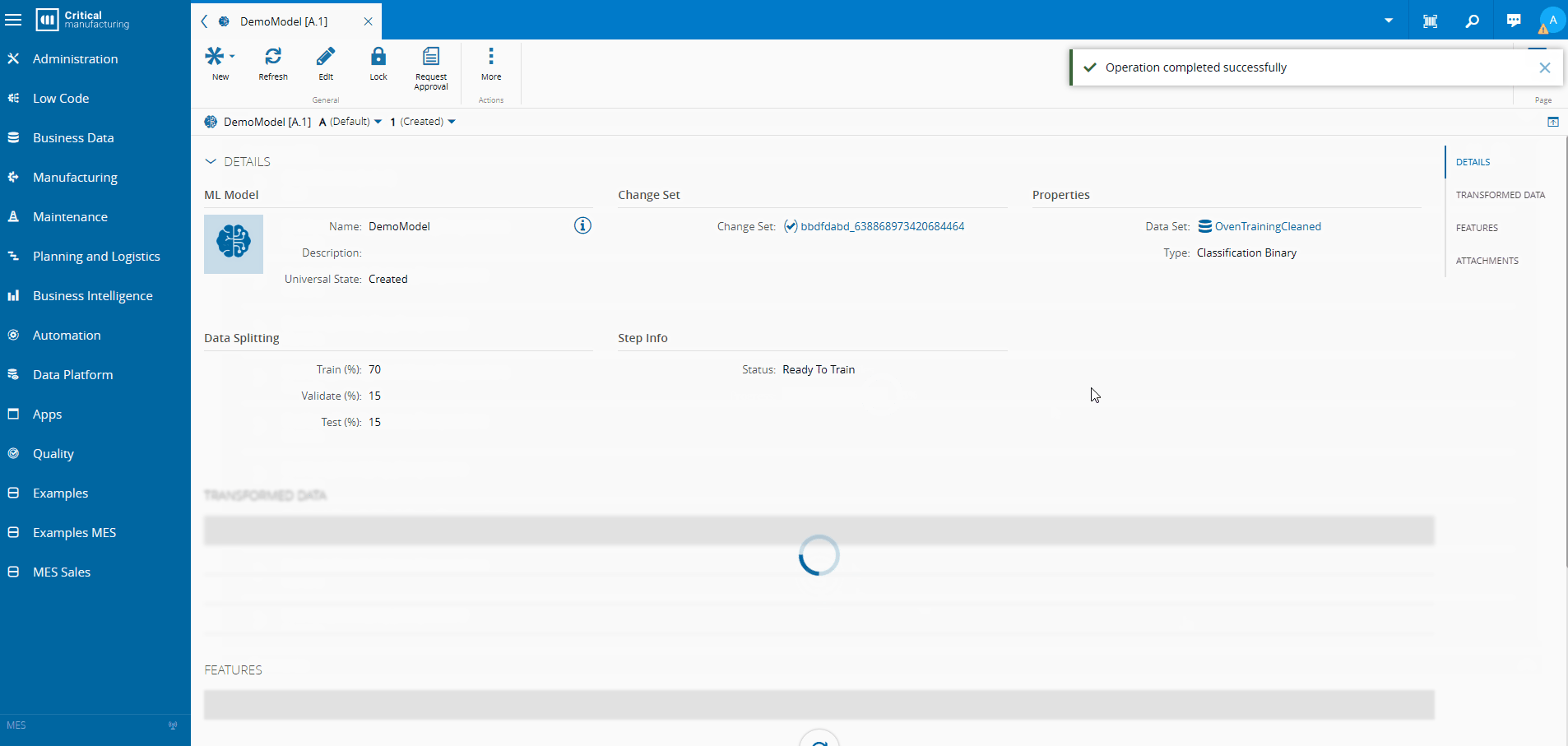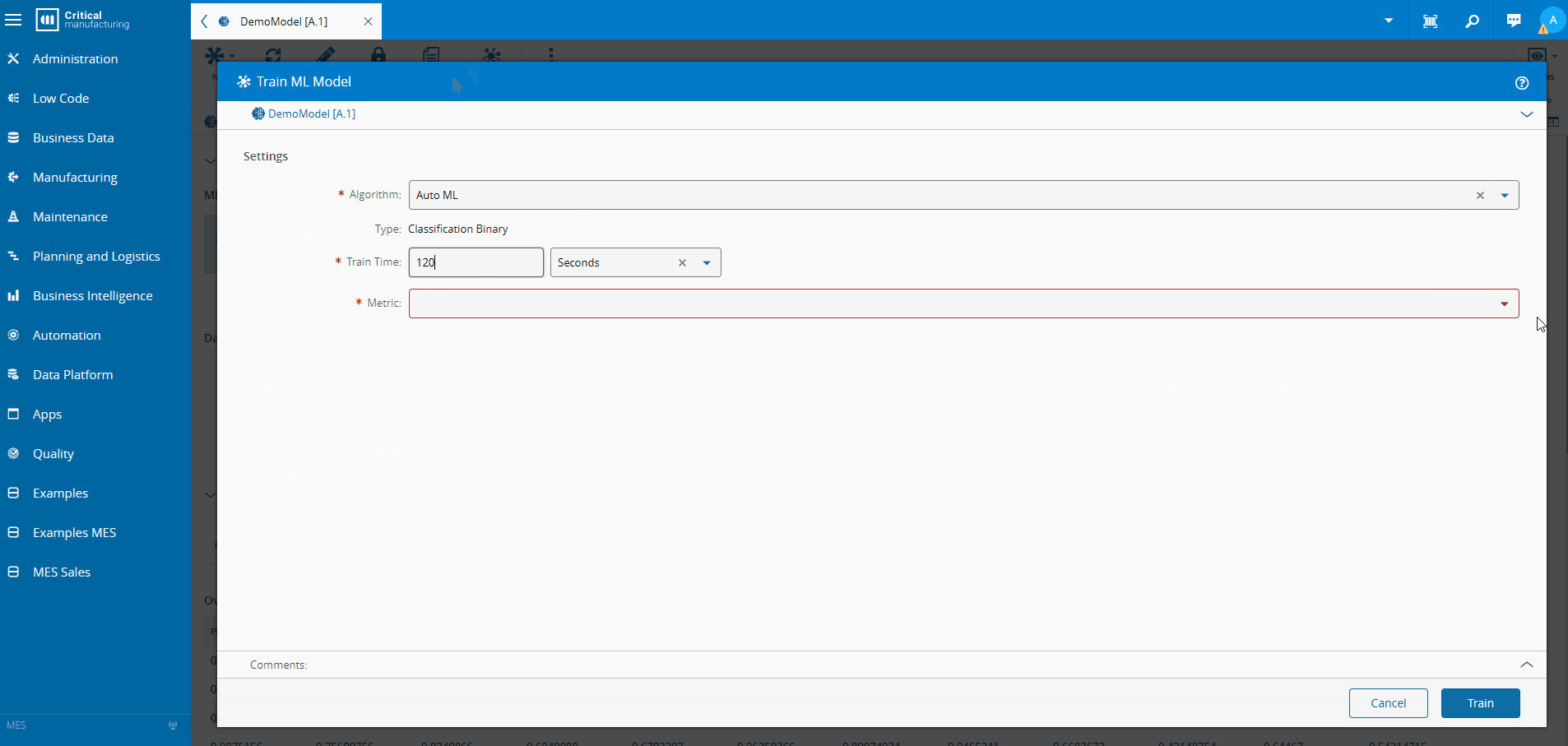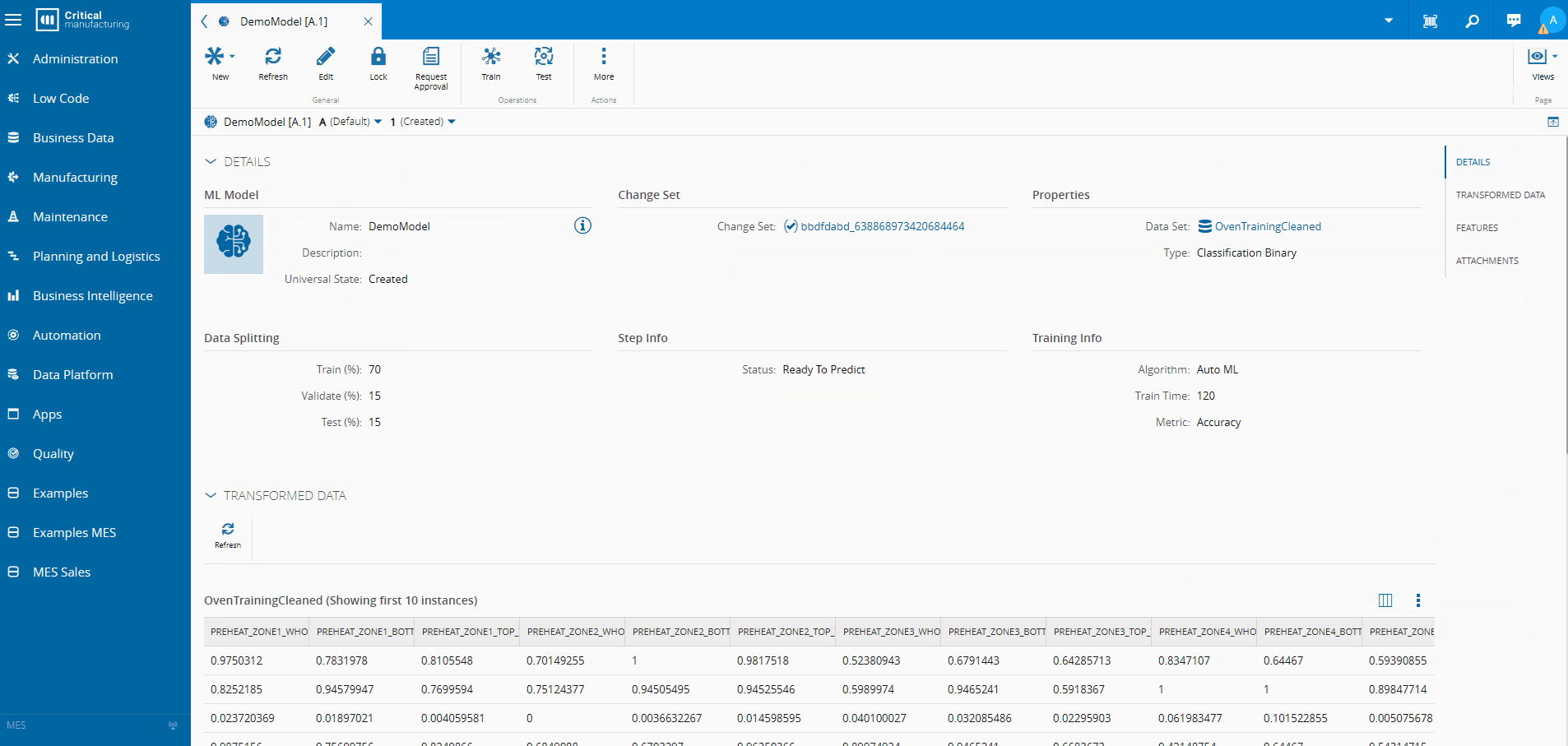
In the MES the user can create their own datasets or use the one’s already provided by the system to train and use their machine learning models.
When producing CDM Events, we can also run additional business logic, perform third party integrations and run our ML Models to perform predictions.

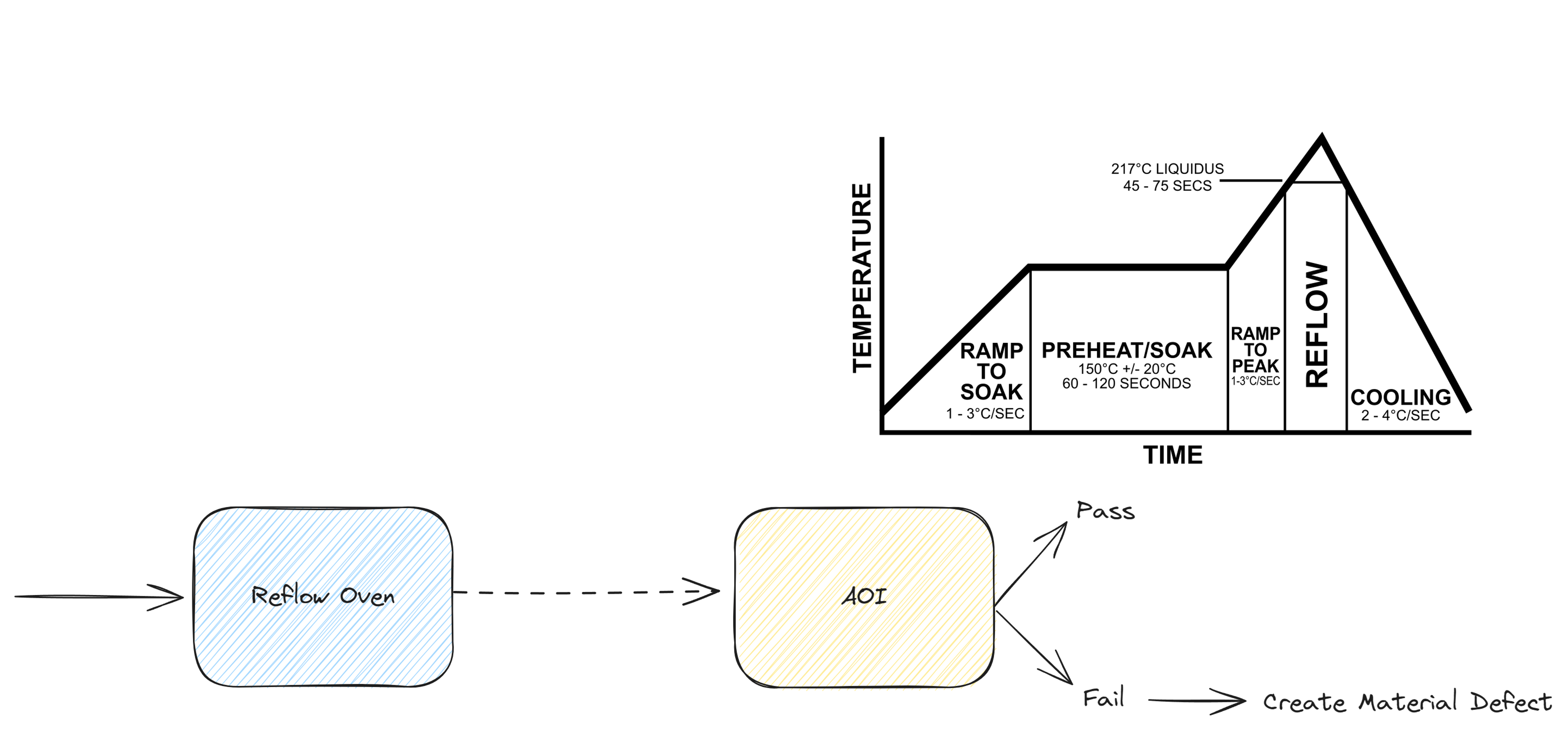
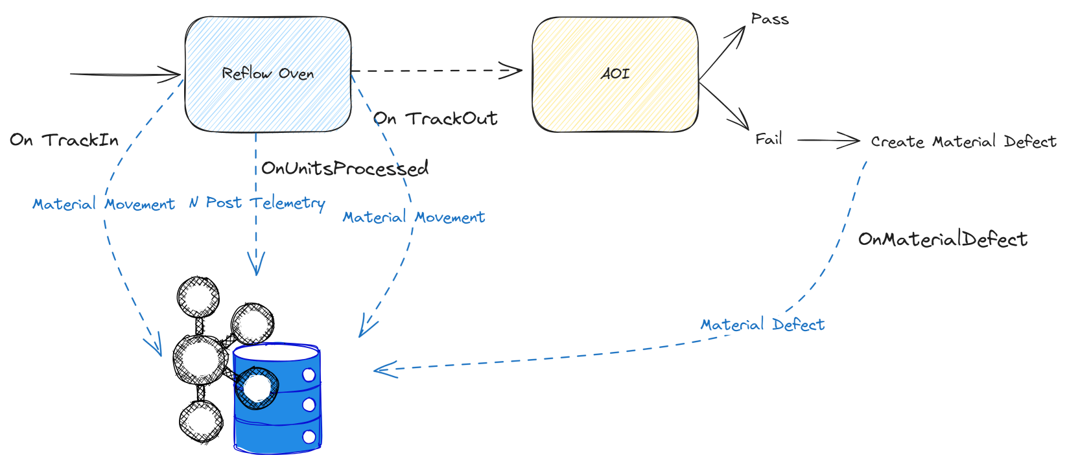
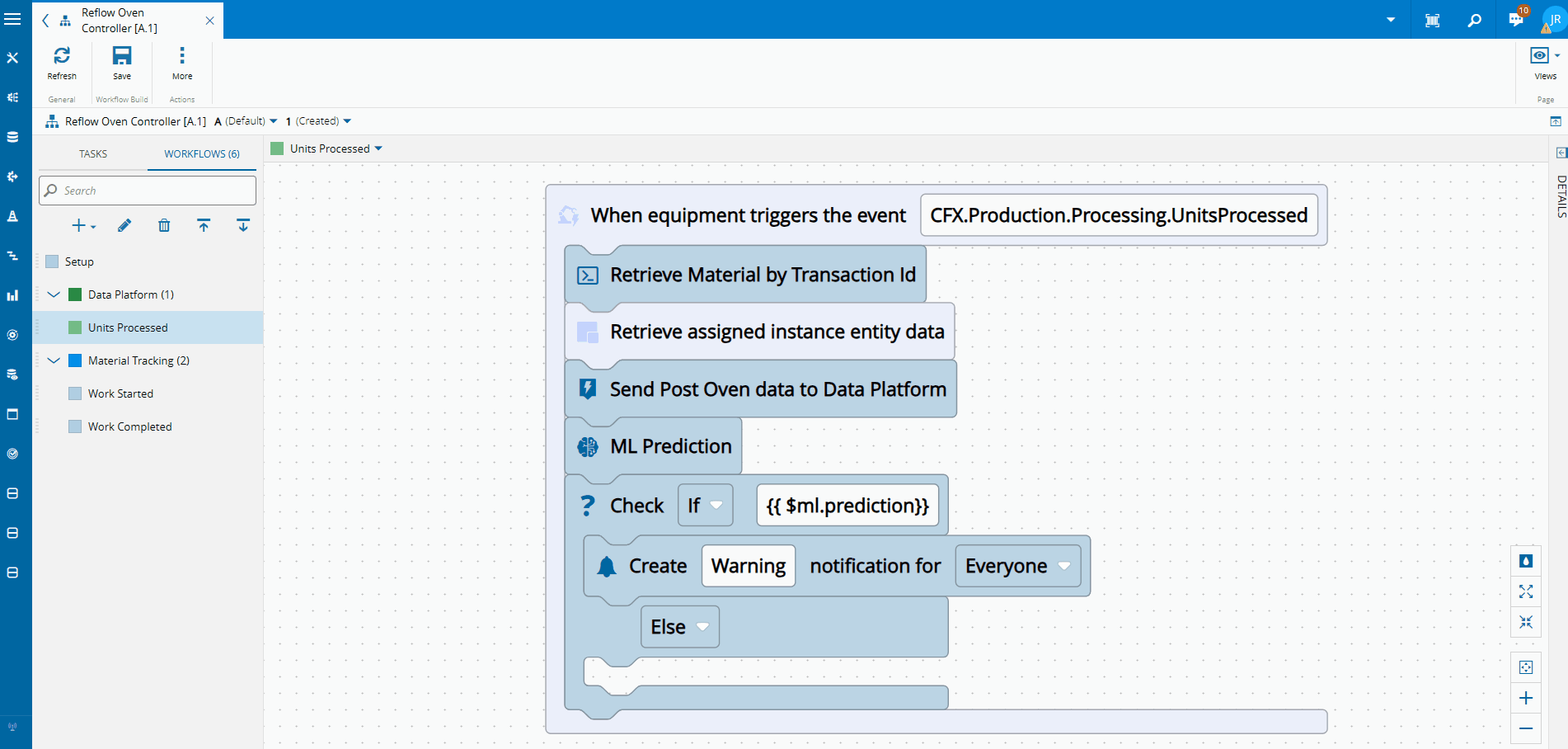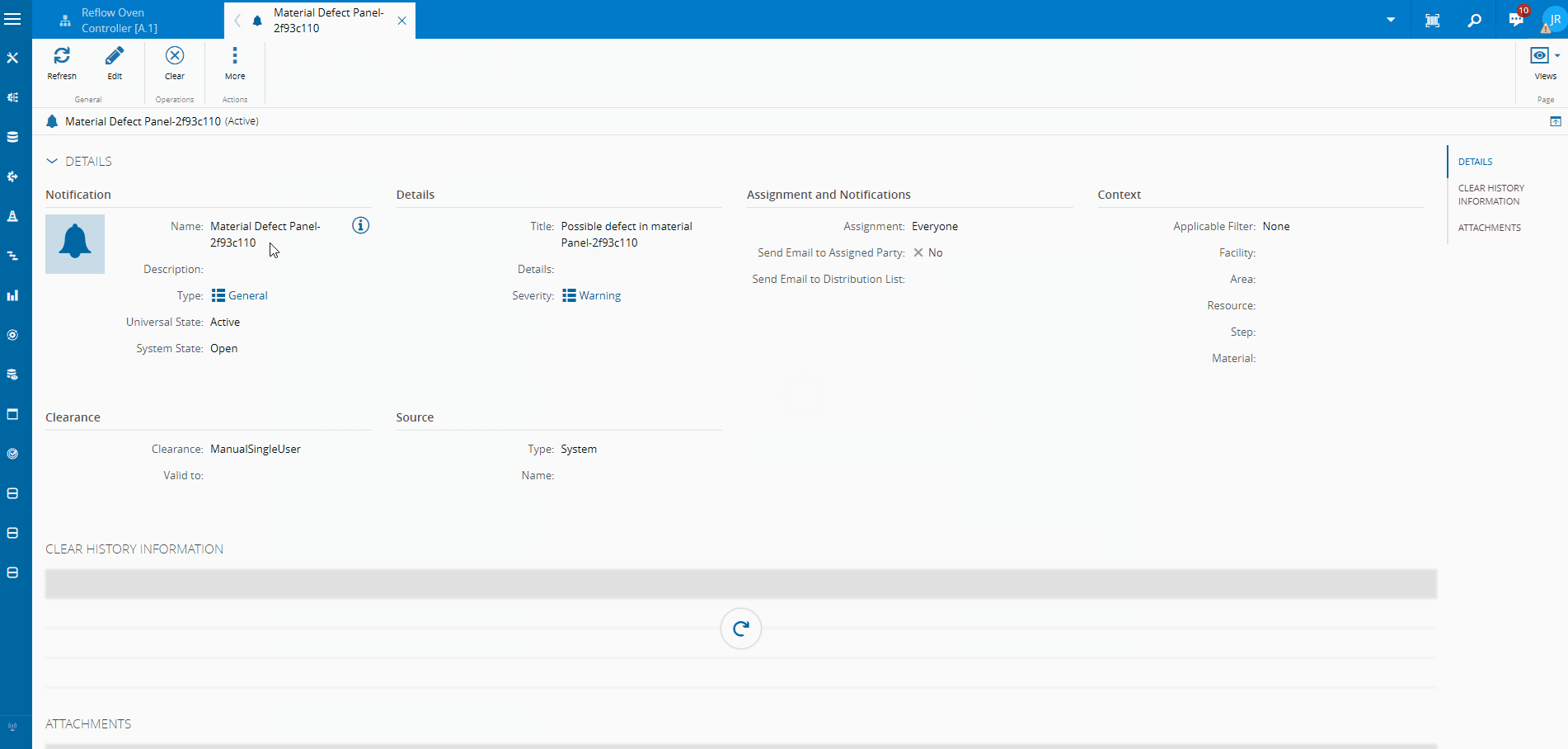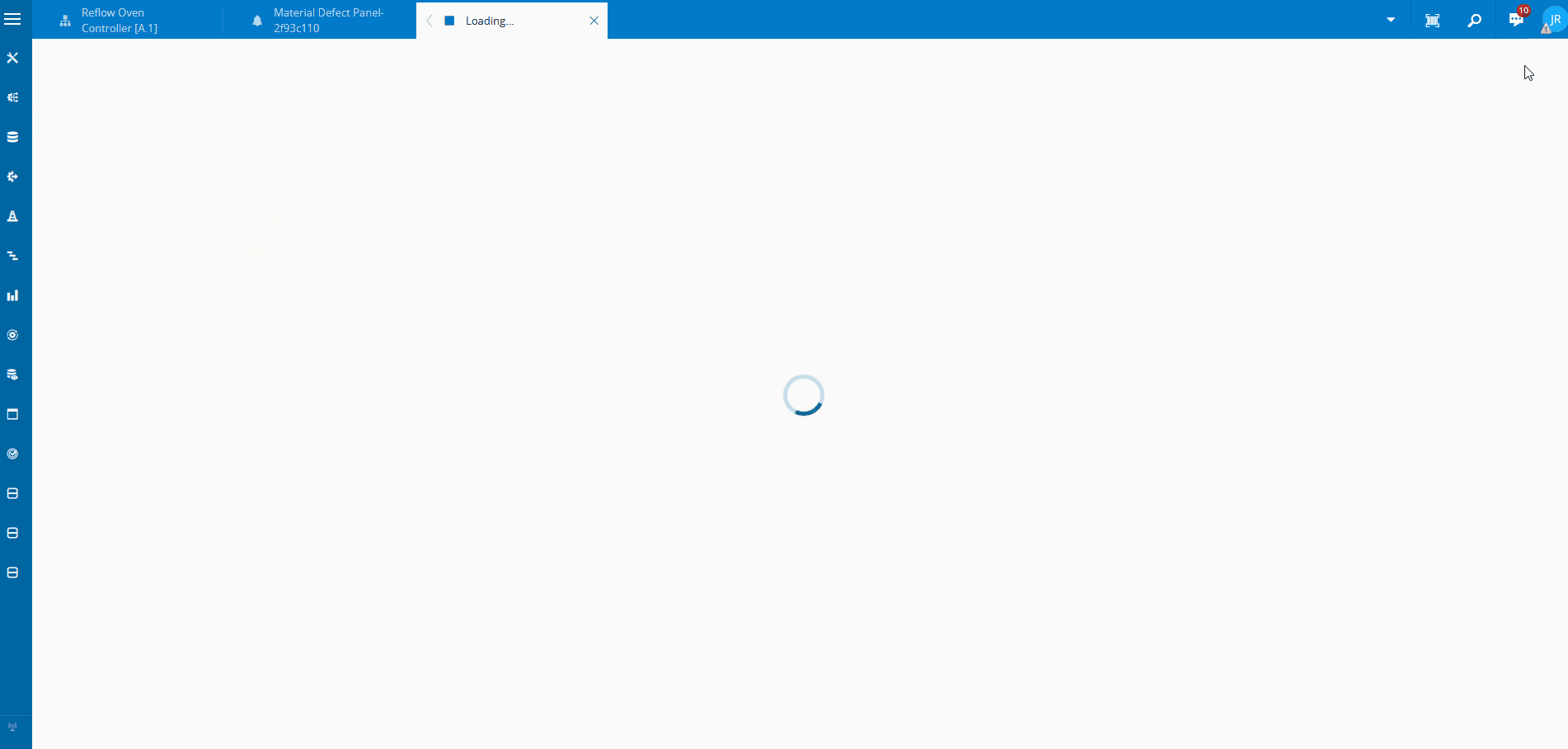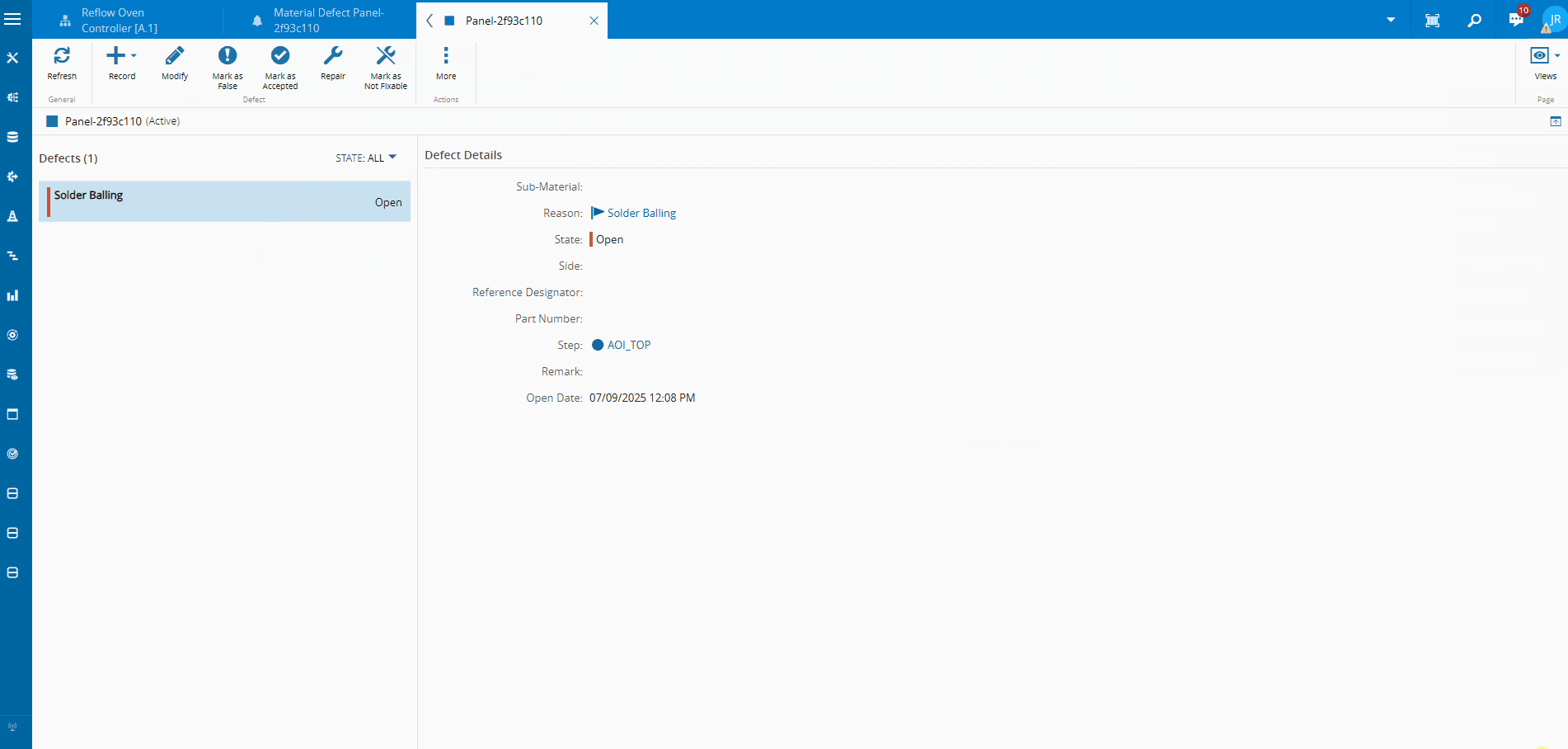
A Simple, Real Use Case: SMT Reflow Oven Defect Prediction#
In an SMT line, the reflow oven melts solder paste so components are fixed to the PCB. Temperature anomalies often lead to solder defects, but these defects are only detected later by visual inspection with an AOI machine.
From the MES perspective:
- Oven temperature data is collected as telemetry (
Post Telemetry) - Material movement is tracked (
Material Movement) - AOI creates defect records (
Material Defect)
This gives us labeled data:
- Inputs: oven temperature profiles
- Output: pass or fail at AOI
From what we saw before, now it’s clear we’ve entered into a supervised learning, classification scenario.
We can already break it down as the set of types of canonical data model events that we will use to create our training dataset.
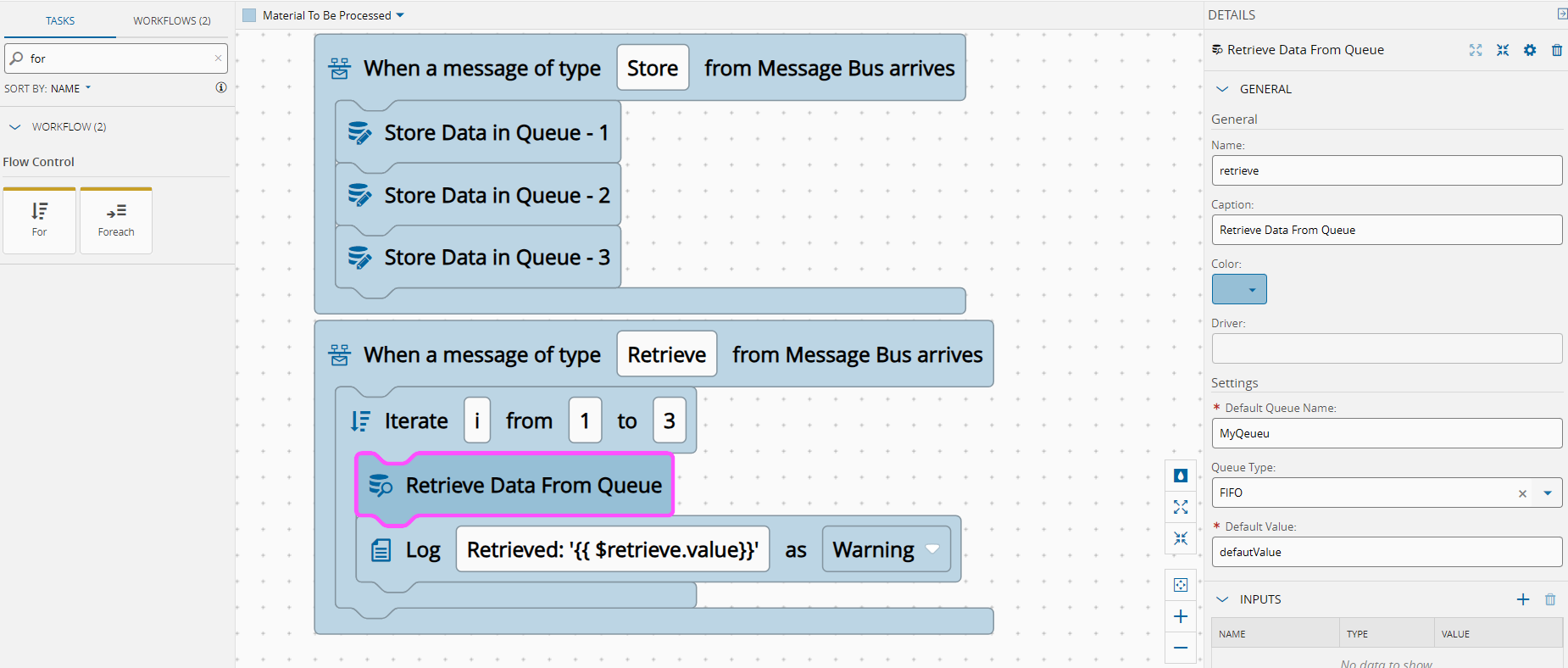
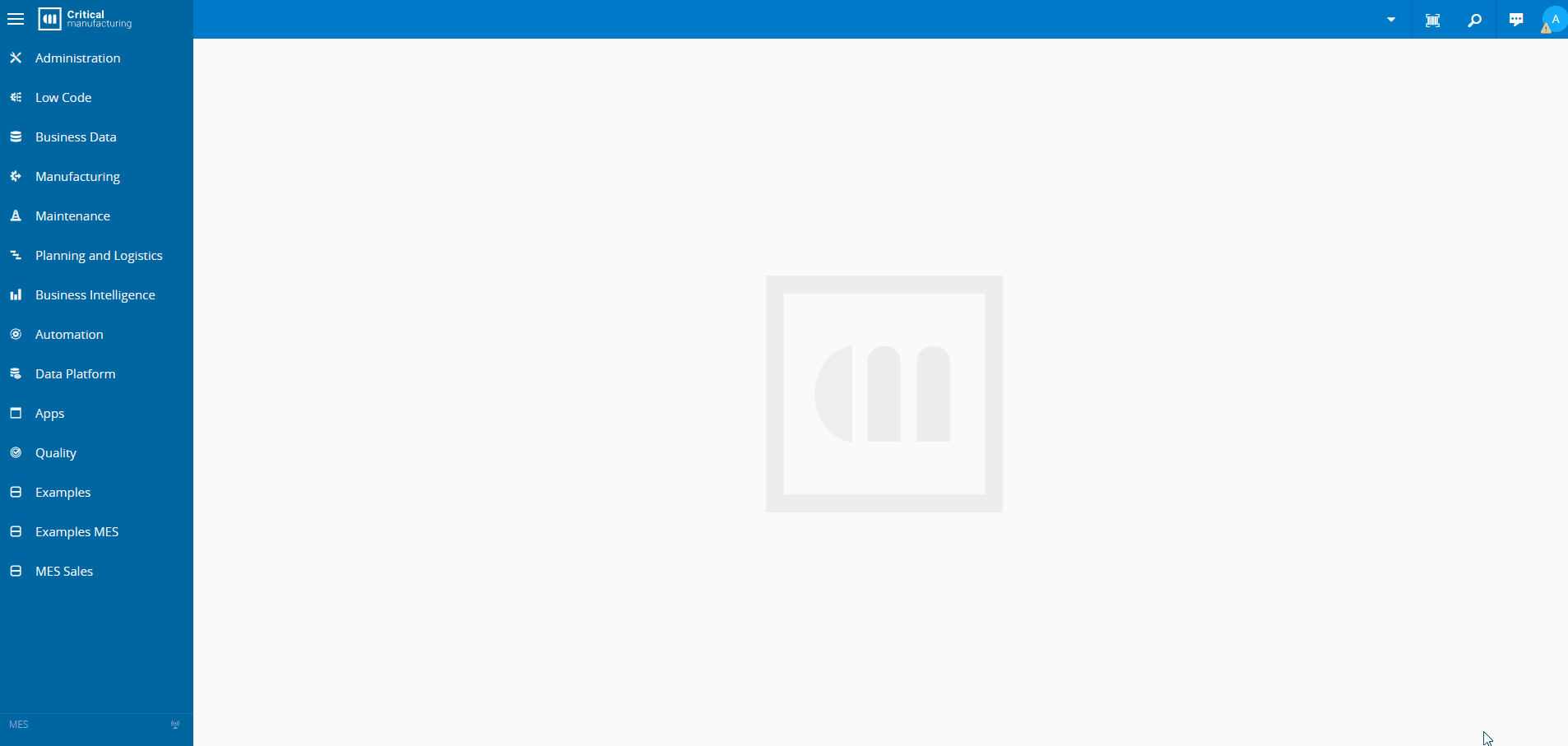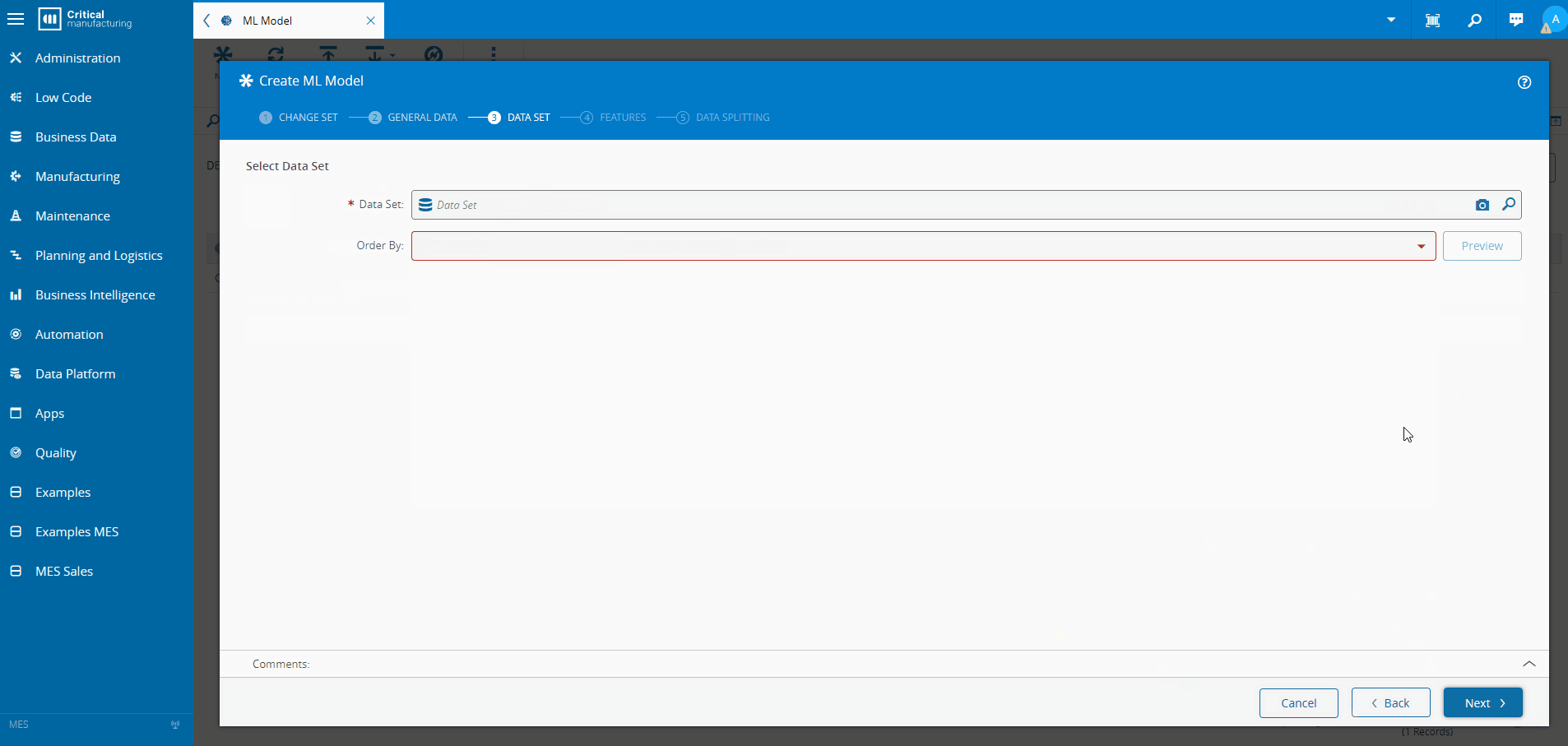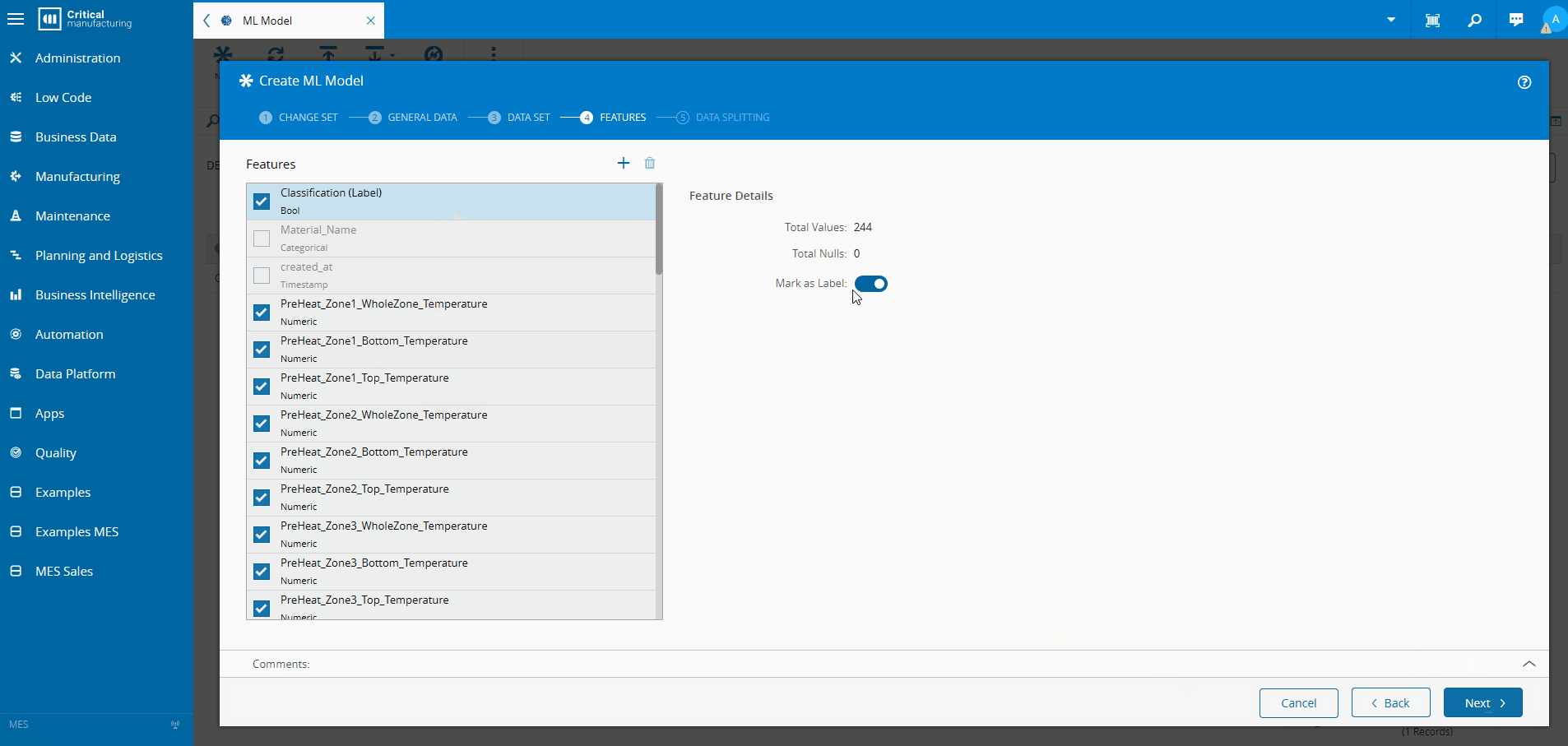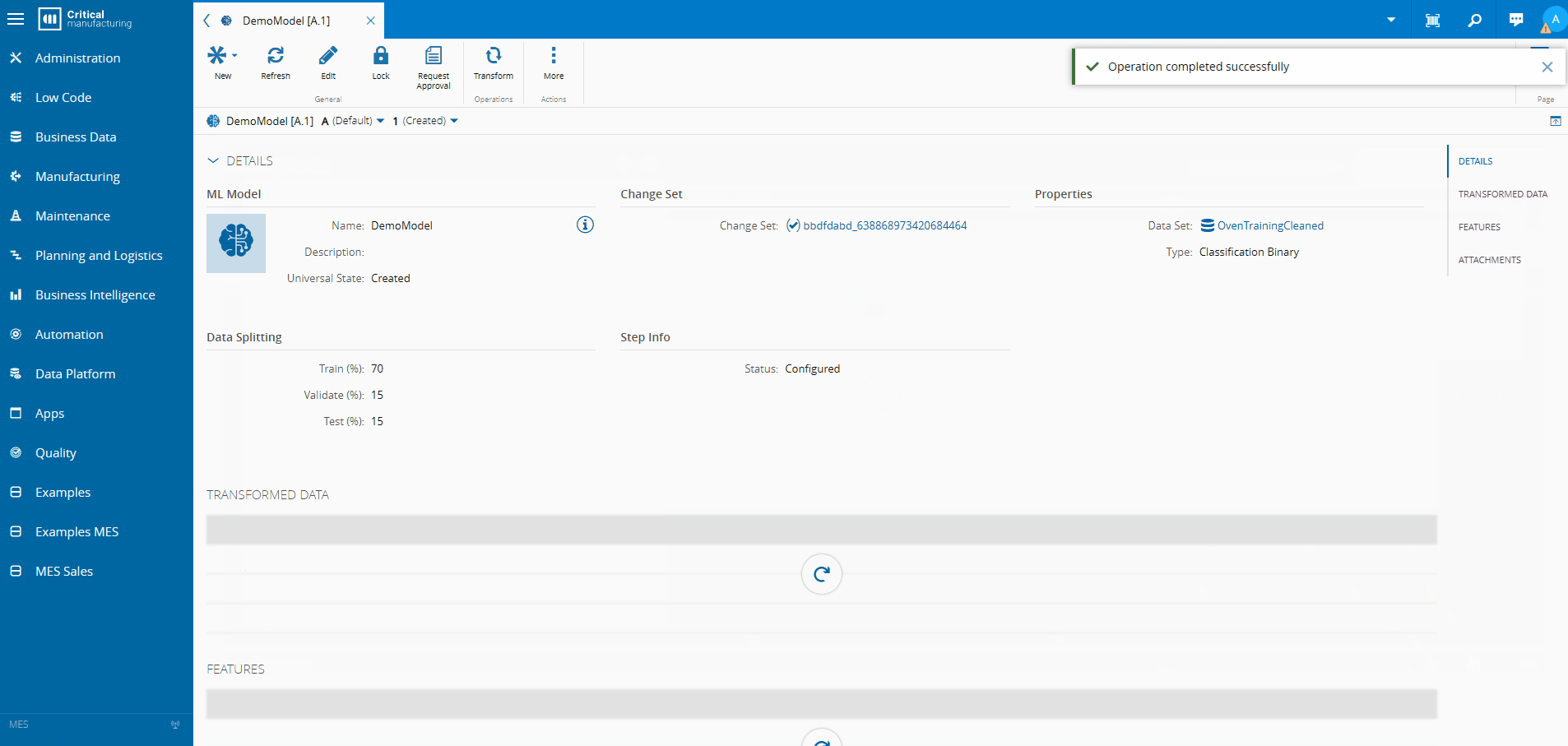
Training the Model Inside the MES#
Using supervised learning:
- Create an MES dataset correlating oven telemetry with AOI results
- Train a classification model using AutoML
- Normalize and validate automatically
- Deploy the model inside the MES
No scripts. No notebooks. No external platforms.
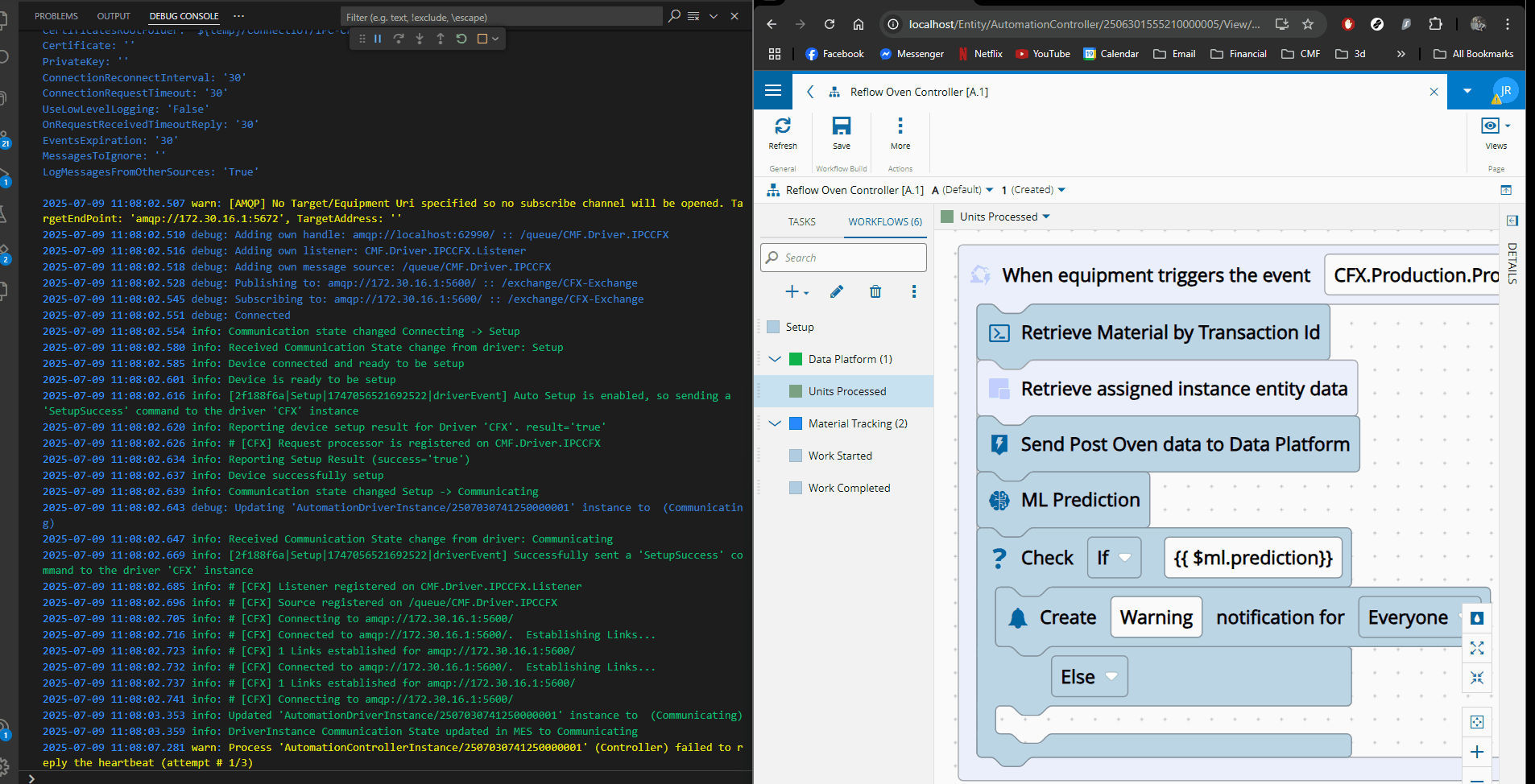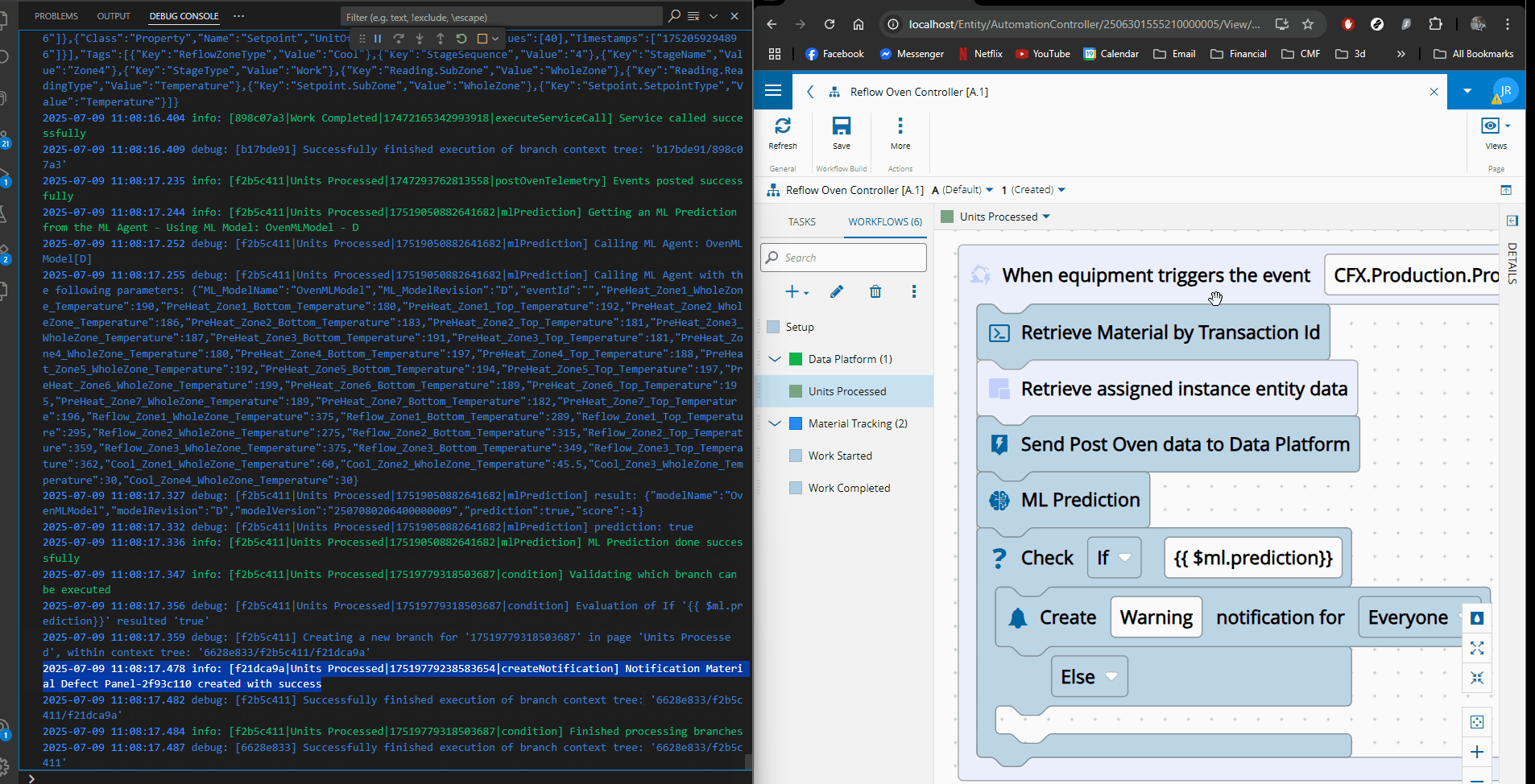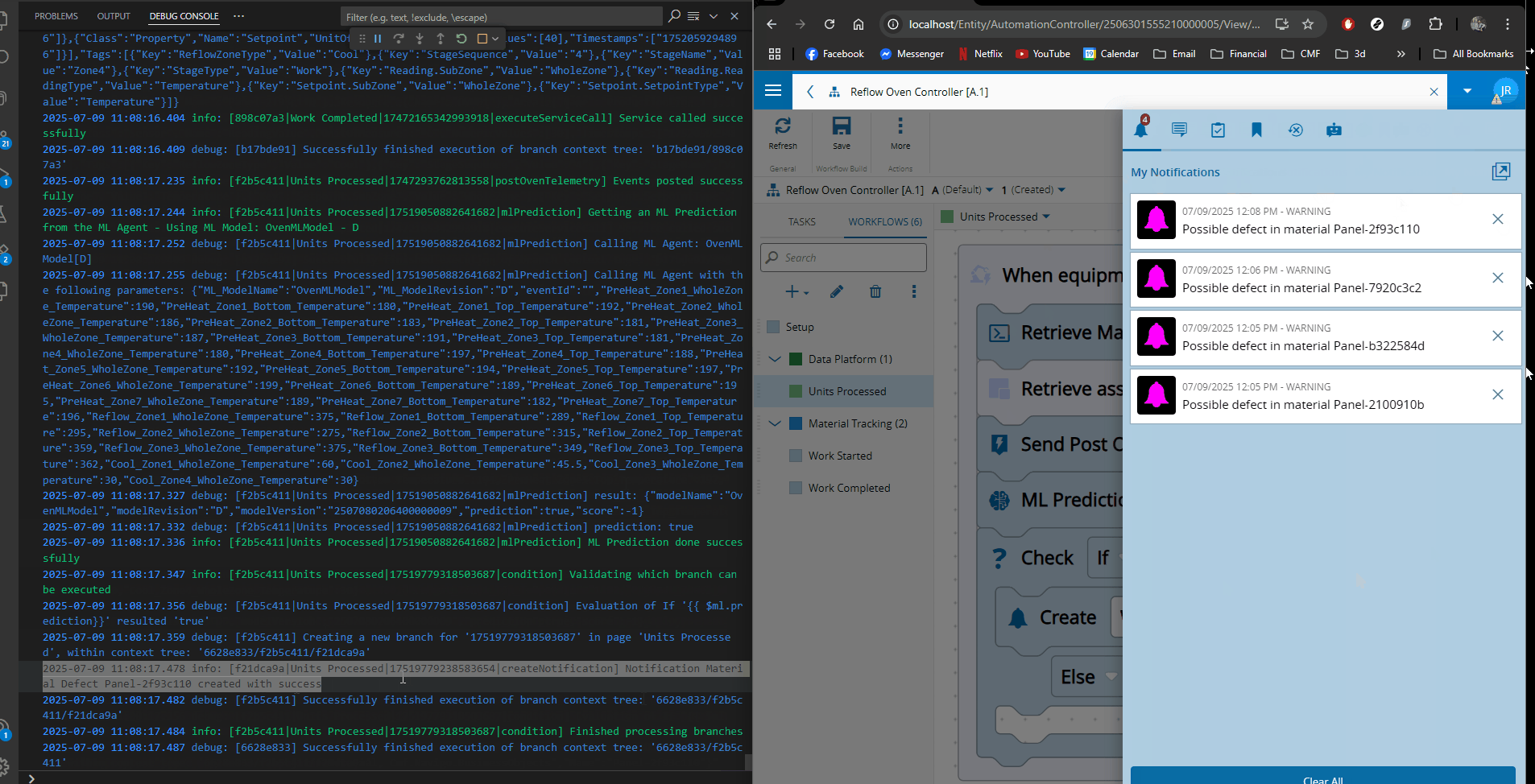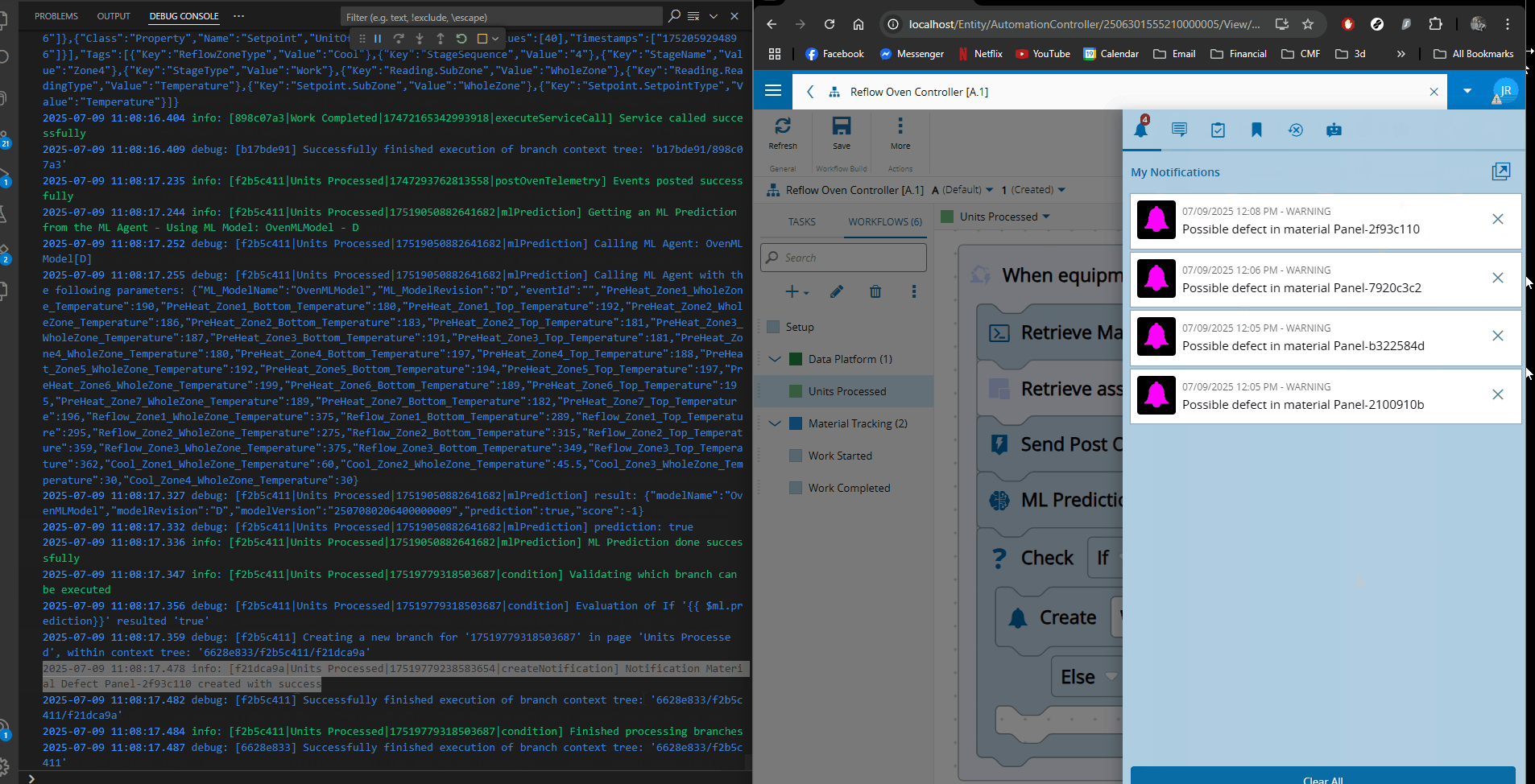
Making Predictions Part of Execution#
Once deployed, the ML model becomes part of the execution flow.
As telemetry is ingested, in the Reflow Oven Integration:
- The MES runs a prediction
- If a defect is likely, a workflow is triggered
- Notifications or actions occur immediately

Defects are no longer discovered only at inspection — they are anticipated.
Other Examples#
Outlier Detection#
Outlier detection is a process of identifying data points that deviate significantly from the normal pattern in a dataset. These outliers often indicate potential issues such as equipment failures, anomalies in production, or irregular environmental conditions.
By setting up an outlier detection low code workflow, in CM MES you can:
- Proactively address issues before they escalate.
- Monitor production data for unusual trends.
- Integrate alerts and actions for seamless operations.
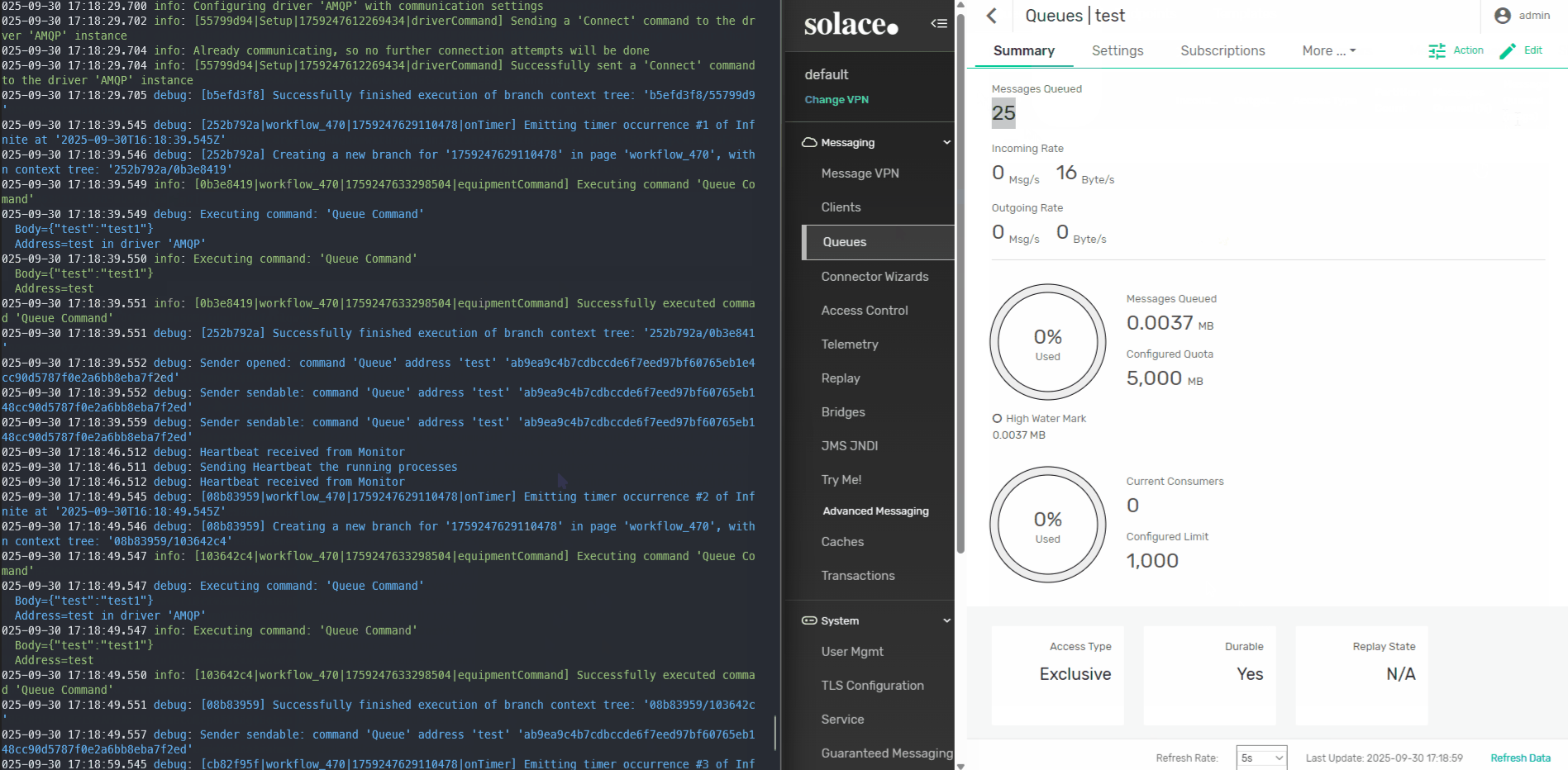
For this particular use case we have a sample with two clear patterns. We need a quick way of segmenting data into two groups: normal and abnormal.
For that we will use isolation forest algorithm provided by Data Platform.
Data Platform comes out of the box with a large selection of algorithms, choose the one more appropriate to your goal.
We will have a low code workflow that is using the machine learning task with the above model to generate predictions. We are then sending the prediction value into a new IoT Event.
In order for us to be able to see the algorithm selection we created a Grafana dashboard that looks into all the stored values for the new IoT Event.
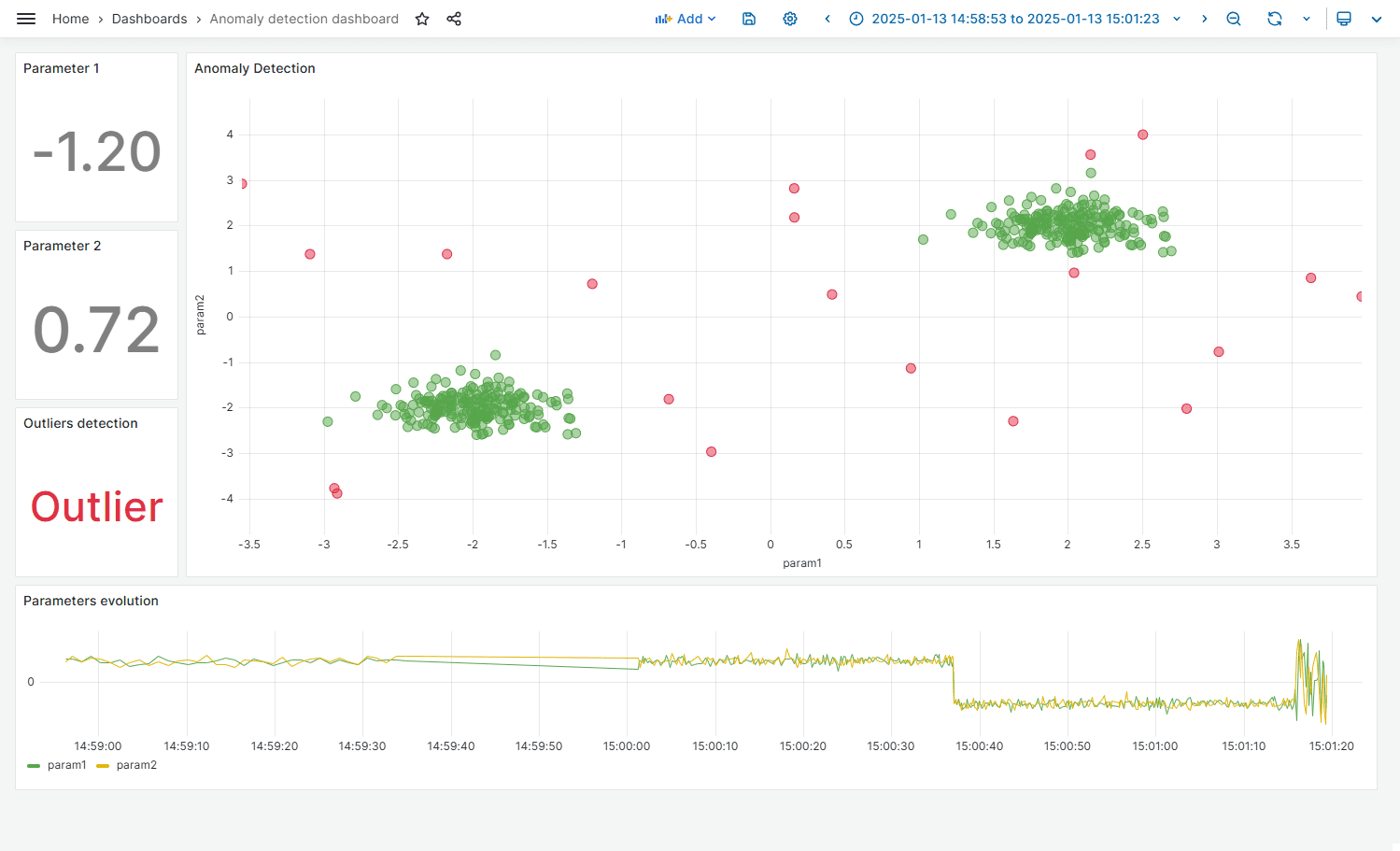
In the dashboard we can easily see two clusters of data and some anomalies. In our low code workflow we are just visualizing the data, but as mentioned above we could perform further actions depending on the prediction.
Predictive Maintenance#
Predictive maintenance has become a cornerstone of the next leap of modern smart manufacturing, and this milling machine use case demonstrates how operational data can be transformed into actionable insight.
By continuously collecting telemetry such as tool wear, temperatures, torque, rotational speed, and power consumption, the system moves away from reactive maintenance and toward a data-driven, proactive approach. Instead of relying on fixed schedules or operator intuition, maintenance decisions are informed by real machine behavior and statistically validated failure patterns. With an MES we are able to use not only machine data, but also process data, product data and past maintenance data.
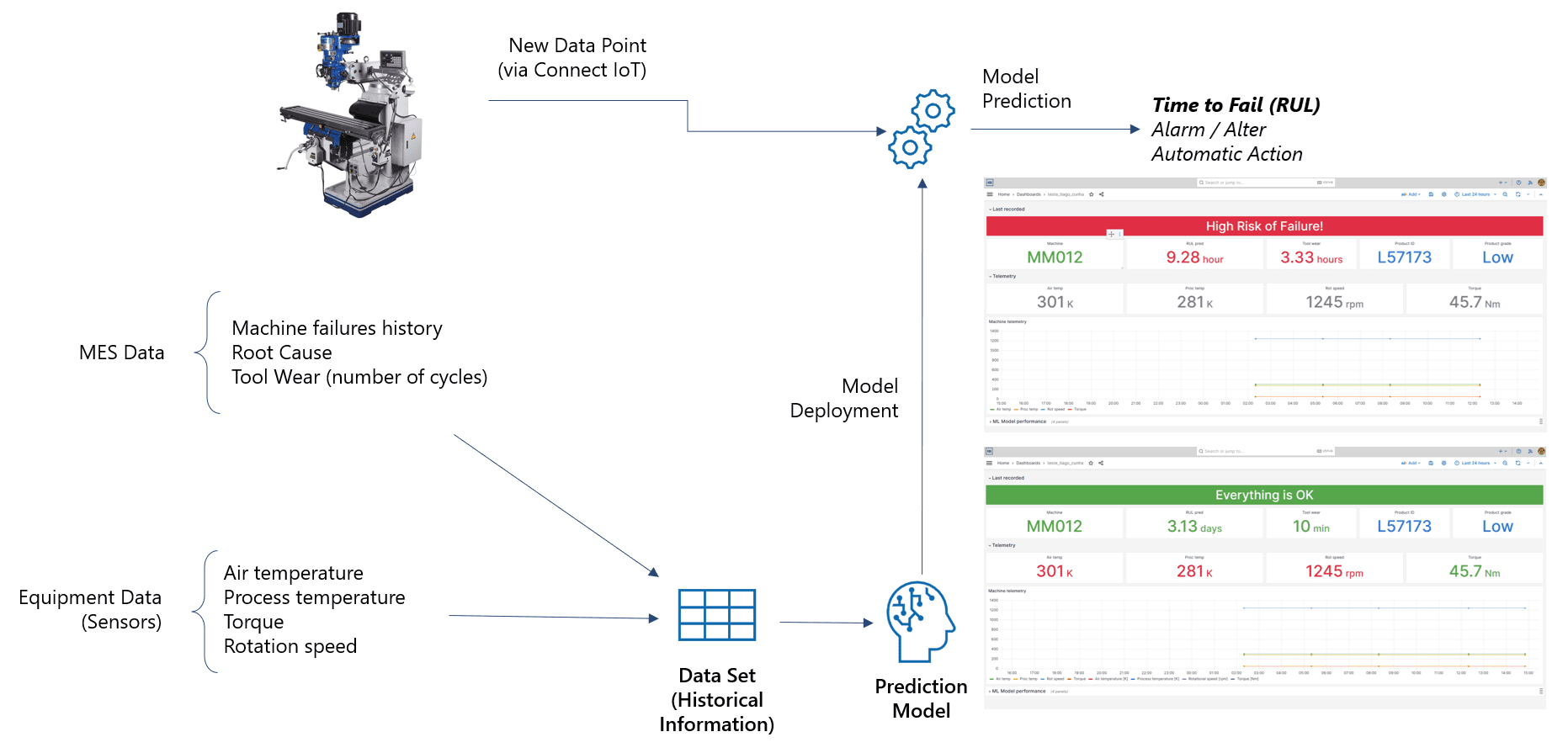
At the core of the solution is a machine-learning model that estimates Remaining Useful Life (RUL) and classifies multiple failure modes, including tool wear, heat dissipation issues, power anomalies, overstrain, and rare random failures. The model is trained on historical production data and automatically optimized using an AutoML approach, allowing teams to focus on domain knowledge rather than algorithm selection. This design makes the solution both robust and maintainable, while ensuring predictions remain aligned with real-world operating conditions
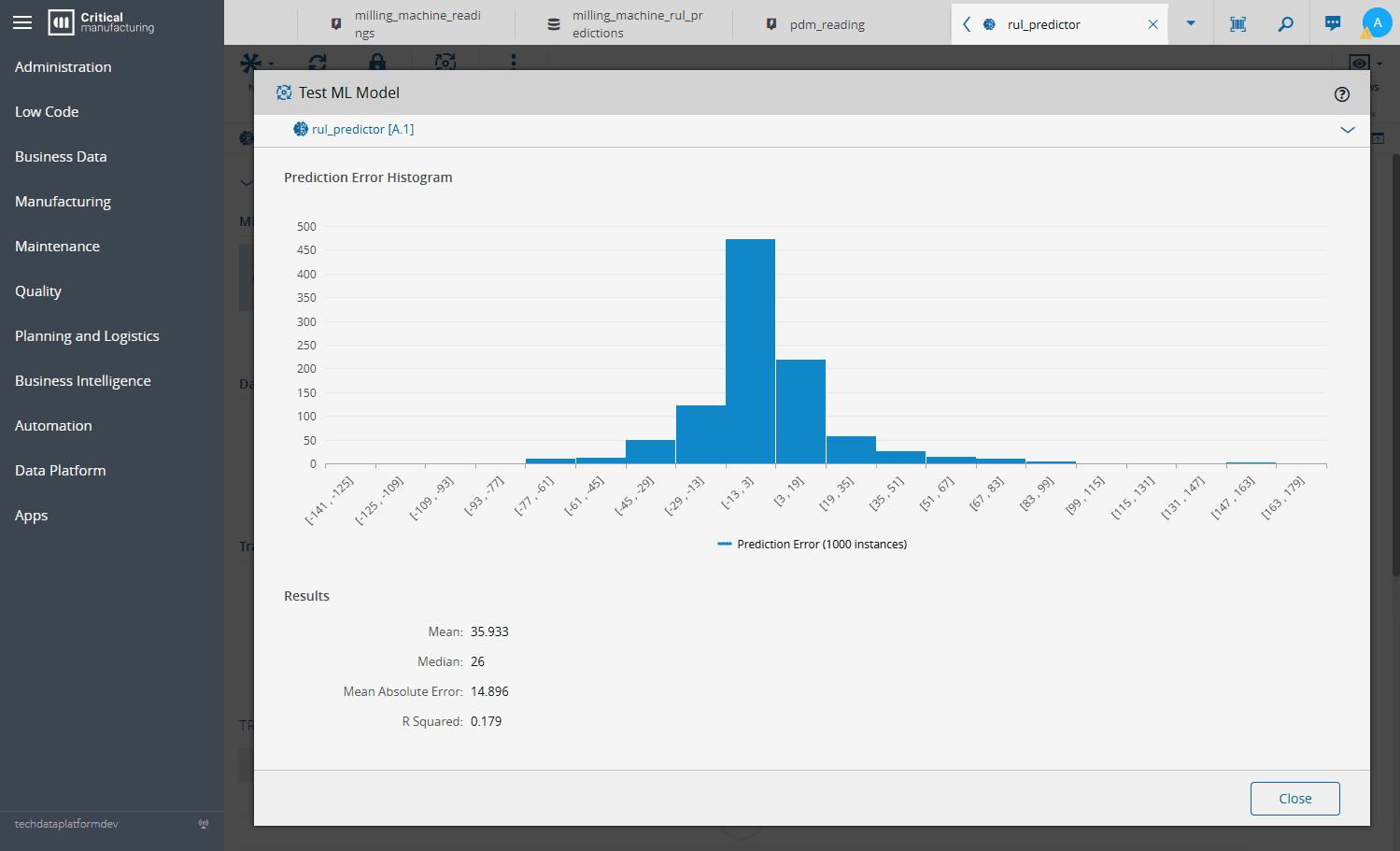
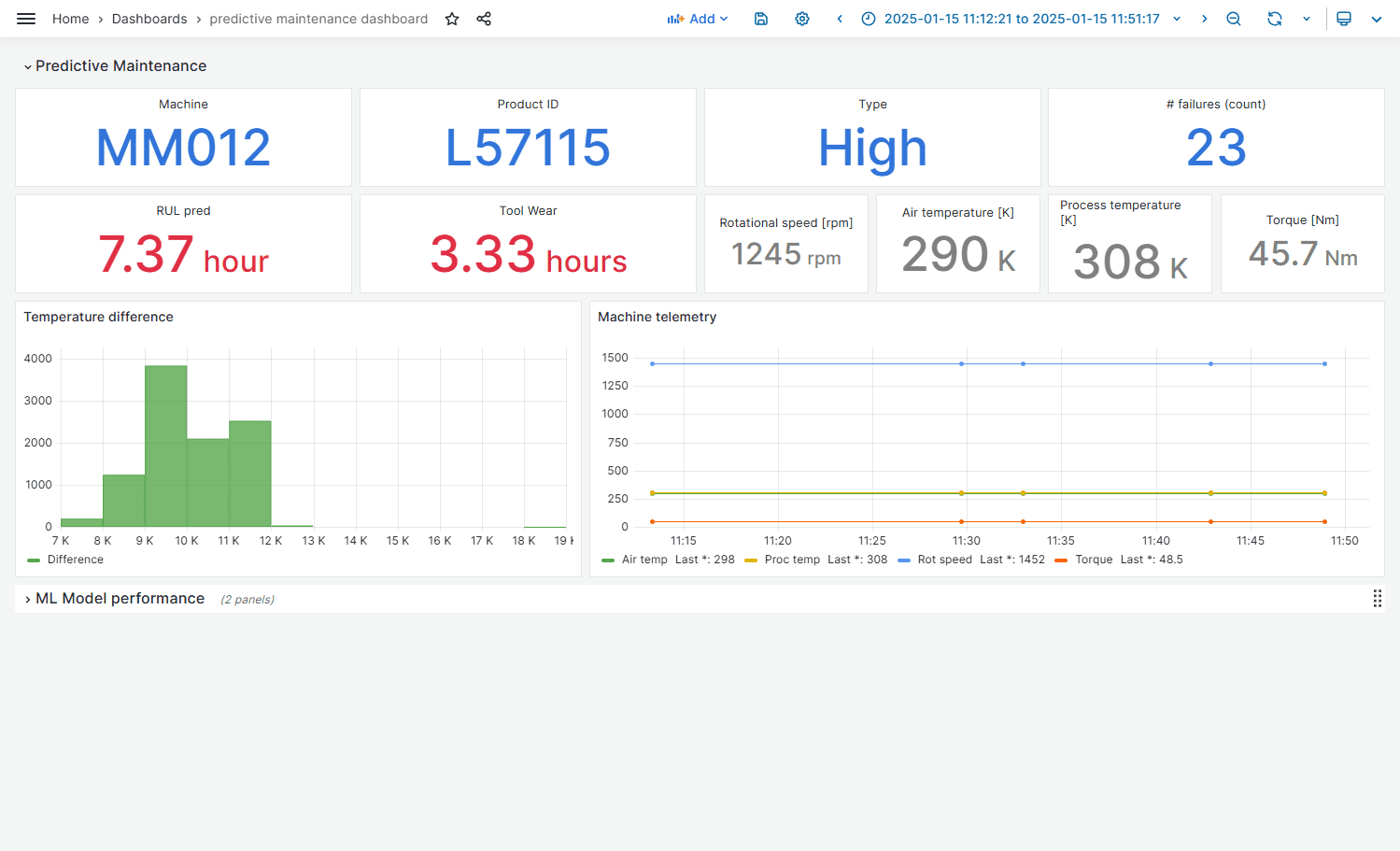
Incoming IoT events trigger predictions that are immediately stored, visualized, and monitored through dashboards, enabling engineers and operators to track degradation trends as they happen. RUL estimates are not static reports but living signals that evolve with machine usage, supporting faster decision-making and reducing unplanned downtime
Ultimately, this predictive maintenance workflow illustrates how advanced analytics can be operationalized at scale. By closing the loop between data collection, machine learning, and live monitoring, manufacturers gain earlier failure detection, improved asset utilization, and more predictable production outcomes. The result is a practical, production-ready example of how AI can deliver measurable value on the shop floor today—not as an experiment, but as a core operational capability.
As in the outlier, we can either perform actions based on predictions or setup dashboards to bring visibility.
Machine Learning as a Feedback Loop#
Machine learning is not a one-time project.
Models:
- Learn from historical data
- Predict future outcomes
- Receive feedback from reality
- Improve continuously
MES systems naturally support this loop because outcomes are always recorded. ML becomes a continuous improvement mechanism, not a static tool.
Final Thoughts#
The SMT oven example is intentionally simple:
- One resource
- One outcome
- One prediction
And yet, it delivers real value. Imagine a applying the same mindset to your whole to crossing information from the whole factory.
If you already use a CM MES you already have:
- The data
- The structure
- The context
- The execution layer
Machine learning simply connects the dots.
Which problems are you already solving manually that the MES could help you predict instead?